

Overfill: Two-Stage Models for Efficient Language Model Decoding
 Woojeong Kim
Cornell
Woojeong Kim
Cornell
Junxiong Wang
Together AI
Jing Nathan Yan
Cornell

Alexander M. Rush
Cornell
Conference on Language Modeling, 2025
Abstract
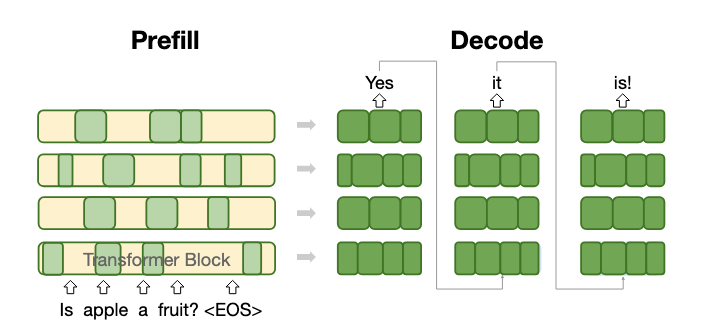
Large language models (LLMs) excel across diverse tasks but face significant deployment challenges due to high inference costs. LLM inference comprises prefill (compute-bound) and decode (memory-bound) stages, with decode dominating latency particularly for long sequences. Current decoder-only models handle both stages uniformly, despite their distinct computational profiles. We propose OverFill, which decouples these stages to optimize accuracy-efficiency tradeoffs. OverFill begins with a full model for prefill, processing system and user inputs in parallel. It then switches to a dense pruned model, while generating tokens sequentially. Leveraging more compute during prefill, OverFill improves generation quality with minimal latency overhead. Our 3B-to-1B OverFill configuration outperforms 1B pruned models by 83.2%, while the 8B-to-3B configuration improves over 3B pruned models by 79.2% on average across standard benchmarks. OverFill matches the performance of same-sized models trained from scratch, while using significantly less training data. Our code is available at https://github.com/friendshipkim/overfill.