

SMC-SD Inference Engine v0.2.0




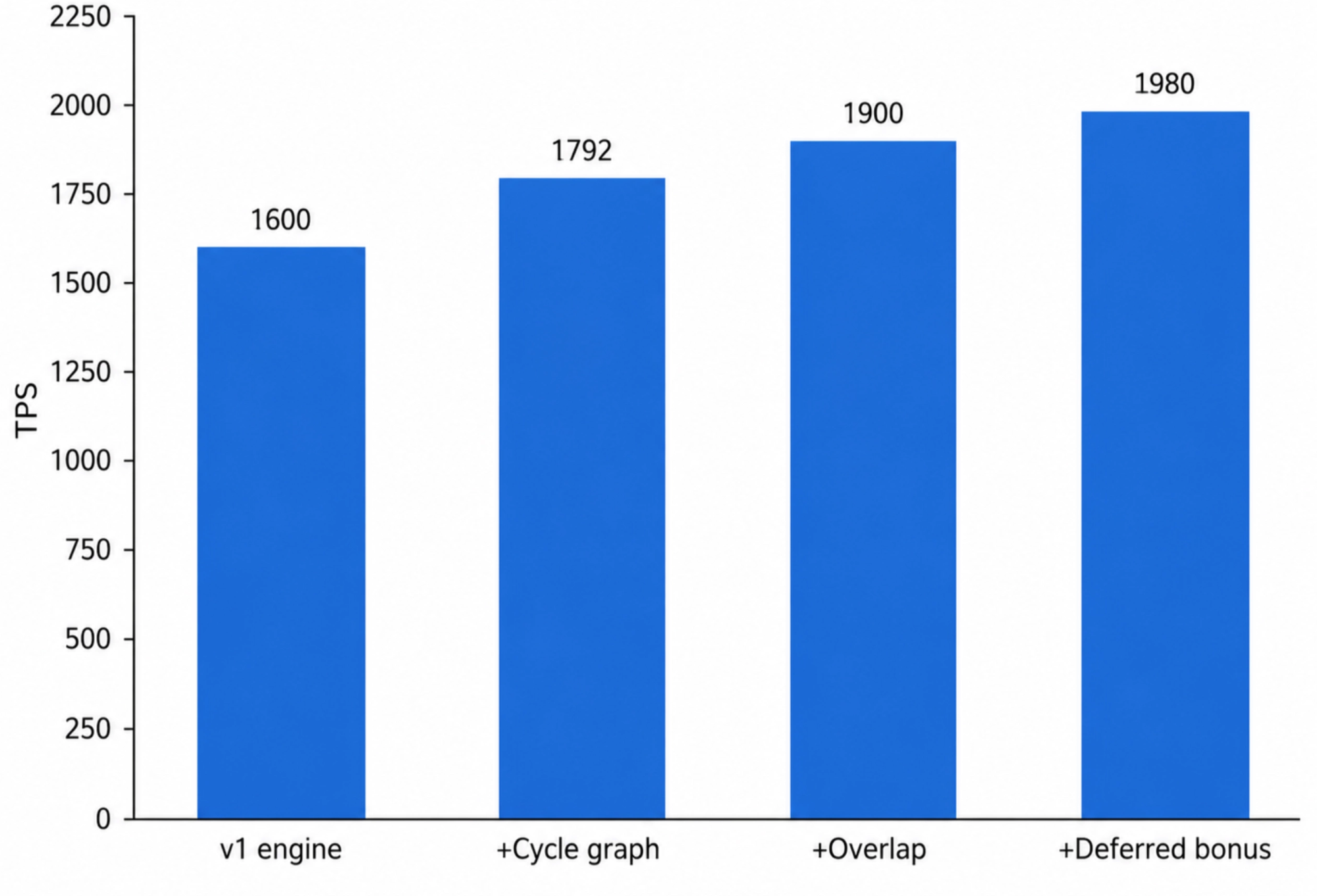
TL;DR: We present a series of SMC-SD engine-level optimizations: refcounted KV prefix sharing, an overlap scheduler that removes decode-loop DtoH syncs, a deferred bonus token, and full-cycle CUDA graphing with a graph-safe Gumbel-max sampler. Together, this makes our v0.2.0 SMC-SD engine ~22% faster with no change to the algorithm or its outputs.
1. Introduction
In this blog post, we look back at our SMC-SD inference engine, which achieved strong performance results relative to existing speculative decoding algorithms, and we discuss new optimizations that make our v0.2.0 engine significantly faster.
What SMC-SD is, and why it’s fast. Unlike rejection-based speculative decoding (EAGLE, Medusa, DFlash), which keeps only the longest draft prefix the target agrees with, SMC-SD never rejects. It runs N particles per request; each cycle every particle drafts K tokens from the small draft model, the target scores them in a single forward, and instead of truncating we accept all K tokens and correct via importance reweighting: each particle accumulates a log-weight α·log p_target − log q_draft, particles are resampled across the population, and a bonus token is drawn at the end. So the sequence advances by a guaranteed K+1 tokens every cycle, deterministically, while the particle weights (not the accepted length) carry the correction back to the target distribution. This gives SMC-SD a tunable quality/throughput knob (via N and the power-target temperature) and strong accuracy at high token rates; see the paper [1] for the algorithm, the estimator, and the accuracy/throughput results against baselines.
Where the performance is still on the table. SMC-SD’s no-rejection rule has a second, systems consequence: because no token is ever rejected, the cycle’s execution shape (tensor sizes, kernel sequence, control flow) is fully static and data-independent, fixed before any token is seen. That matters because the bottleneck at batch size 1 is the orchestration. A cycle is many GPU ops (K draft forwards, a target verify, a sampler, a resampler) glued together by host-side Python, kernel launches, and CPU↔GPU syncs, and we measure the bs=1 cycle running at only ~34.5% of the HBM roofline, i.e. ~65% of the wall-clock is bubble, not useful weight-streaming. Rejection-based SD can’t capture a whole cycle ahead of time because its accepted length is dynamic; SMC-SD’s static shape lets us fuse and overlap the bubble away. The rest of this post walks through that stack: refcounted KV prefix sharing to make N particles cheap, an overlapped scheduler that strips the decode-loop syncs, a deferred bonus token that fuses two decode steps into one, and a full-cycle CUDA graph (unlocked by a graph-safe Gumbel-max sampler) that collapses the per-step host dispatch into a single launch, increasing our performance on a B200 GPU by 22%.
2. Efficient Prefix-Sharing via Refcounted KV
When running SMC-SD, each user request fans out into N particles, all starting from the same prompt. Two KV caches are used (for both the draft and target models), and each particle needs the prompt’s KV prefix in both. The naïve implementation would give each particle its own copy of the prefix, which would cost Nx the KV memory. Compounding memory management problems, the N× copy bandwidth hurts fan-out and resample latency.
Prefix sharing itself is not new, as SGLang already shares prompt prefixes across requests through its RadixAttention tree cache, refcounting tree nodes so a shared prefix survives until the last request is done with it. But that machinery is the wrong fit here: our N particles aren’t separate cached prefixes in the tree, they’re N copies of one request that we explicitly detach from the tree cache. The base token allocator we inherit from SGLang has no refcounts of its own. So we add refcounting one level down, per KV slot, to get multi-owner slots within a single request’s particle set — letting all N particles share one copy of the prompt’s KV and, later, letting resampled particles share a surviving sibling’s pages. We leverage this to make running many particles cheap.
In our V1 engine, particles don’t copy KV; they share it, and we track ownership by refcounting pages.
SMCRefCountedTokenAllocator wraps the base allocator with an extra tensor, a per-slot slot_ref_count , and four operations on top of it:
allocsets a slot’s count to 1freesets it to 0inc_refbumps itdec_ref_and_freedecrements and frees slots whose count hit zero.
def dec_ref_and_free(self, indices):
self.slot_ref_count[indices] -= 1
to_free = indices[self.slot_ref_count[indices] == 0]
if to_free.numel() > 0:
self.free(to_free) # returns slots to the pool only on the last owner
A particle’s prefix is just a block table, which is a list of integer slot ids pointing to the shared KV pool. Sharing a prefix means copying those integers and bumping a refcount, while the KV bytes themselves never move.
Fan-out. When a parent request materializes into N particles, copy_block_table clones the parent’s L block-table entries into each particle and inc_refs the L shared slots:
def copy_block_table(req_to_token_pool, src, dst, seq_len, allocator):
copied = req_to_token_pool.req_to_token[src, :seq_len].clone() # L ints
allocator.inc_ref(copied.to(torch.int64)) # share, don't copy
req_to_token_pool.write((dst, slice(0, seq_len)), copied)
After fan-out each of the L prefix slots has refcount N (the parent then releases its reference, dropping from N+1 to N). Total work: O(L) integer copies per particle, zero KV-byte copies.
Resample. Resampling reuses the exact same mechanism. When a low-weight particle is overwritten by a high-weight particle, we copy the high weight particle’s block table over the dead particle’s and inc_ref the shared slots. Again, the KV cache is untouched. This is why the resample kernel only ever moves block-table entries and refcounts, never cache contents. dec_ref_and_free reclaims a slot only when its last particle releases it.
This makes N-particle SMC affordable: particles share a prefix safely and resampling is a block-table shuffle, not a KV copy. Beyond the new tokens each step commits to out_cache_loc (unavoidable, same as any decoder), SMC moves no KV bytes at all.
Note: SGLang already refcounts shared KV as RadixAttention hashes token spans into a radix tree and reference-counts the tree nodes so a prefix shared across requests survives until the last user is done with it. But that machinery is the wrong shape for SMC on two counts. First, its refcount API is per-node and single-node (inc_lock_ref(node) / dec_lock_ref(node)), with no way to bump or drop a batch of slots at once, yet every SMC decode step duplicates and frees slots across N particles and many groups at once, and has to do so without a host sync (see the overlap scheduler). Second, SGLang only registers spans into the radix tree at request boundaries, after prefill finishes, when a request finishes, or on retraction, but never during decoding, which is exactly when SMC’s sharing is created and destroyed by fan-out and resampling. So rather than fight the tree-cache API, we add a thin per-slot refcount layer of our own: the base TokenToKVPoolAllocator we inherit from SGLang has no refcounts, and we add them.
3. Overlapped Scheduling
Here is a code block showing the hot-path of the V1 engine’s event loop—-the core scheduler loop that fetches requests and dispatches work to the GPU.
def _event_loop(self) -> None:
while True:
batch, batch_kind = self._get_next_batch() # preprocess inputs
result = self.run_batch(batch) # run SMC-SD cycle on inputs
self._resample(result) # resample
self._process_decode_result(result) # process the results
The timeline for this event loop looks like this:

There are roughly 3 distinct steps here:
- Preprocess:
- Allocates KV pages for draft and target models.
- Run batch:
- Initiates drafting, verifying, sampling, and resampling
- Postprocess:
- Detects EOS tokens and drains requests that have finished.
- Frees KV pages associated with particles that haven’t survived resampling and from requests that have finished.
The problem with this event loop is that it leaves a lot of idle GPU time between SMC-SD steps. The GPU sync with the CPU between each SMC-SD step waits for the CPU to schedule the next batch. This observation motivates trying to keep the CPU scheduling work overlapped with the GPU’s workload. With overlapped CPU scheduling, our timeline looks like this:

The GPU bubble between SMC-SD cycles effectively disappears!
3.1 Removing CPU-GPU roundtrips Syncs
Before we can fully overlap CPU scheduling with GPU work, we need to remove a key blocking device-to-host (DtoH) sync on the decode hot path. Our resampling step involves (1) drawing random samples to determine which particles are duplicated and which are eliminated and (2) reshuffling KV cache pages given the plan from the previous step. In our V1 engine, the dispatch grid of the kernel that did (2) depended GPU-resident data after completing step (1), forcing a DtoH sync. Crucially, this step also cannot be pushed to the post-processing stage where the CPU work will overlap with the GPU as the next SMC-SD step needs to know which pages are associated to each request in a batch. We this sync by dispatching the KV reshuffle kernel with a loosely upper bounded grid that keeps its shape static, and by always launching the KV reshuffle kernel even when it is a no-op (for instance, when the effective sample size is not below the resampling threshold). The loose upper bound we use for the KV reshuffle kernel leads to considerably more threads being dispatched on the GPU that do wasteful work; the kernel goes from 2us to 5us. Moreover, even when no particles are resampled and no GPU work is needed, we dispatch the KV reshuffle kernel, anyway, to avoid branch logic that would force a DtoH sync. Both of these penalties are considerably less than the cost of moving data between the GPU and CPU and are worth it to keep GPUs brr’ing.
3.2 Overlapped Scheduling Event Loop
After removing the blocking DtoH sync between SMC-SD steps, we are left with two non-blocking procedures that run on the CPU:
- Freeing KV pages for particles that have been killed (needs
n_freedfrom the GPU) - Draining requests that have seen an EOS token (needs the
finished_maskvariable from the GPU)
Instead of relying on .cpu, .item, or .tolist, which would force a drain of the CUDA stream, the resample method does a .copy_ from a GPU buffer to a pinned CPU buffer with non_blocking=True and emits a CUDA event to signal that the DtoH copy has occurred. The post-process step waits for the CUDA event to signal that the CPU buffers are ready. When the post-process step unblocks, the data is retrieved and the post-processing logic proceeds on the host.
Once we’ve made these changes, we can implement our overlapped scheduler event loop. After batch t enters the queue, the post-processing step waits for the result of batch t-1 to arrive to the CPU. Concurrently, the GPU starts to run batch t’s forward pass on the GPU since it has already been queued.
def _event_loop_overlap(self) -> None:
result_queue: Deque = deque()
while True:
batch, batch_kind = self._get_next_batch() # get inputs for step t+1; preprocess
result = self.run_batch(batch) # launch step t+1 SMC-SD cycle
snapshot = self._resample(result) # resample; snapshot is a CUDA event that waits
# until step t's data has been copied to CPU
result_queue.append(
("decode", batch, result, snapshot) # add to queue
)
while len(result_queue) > 1:
self._process_queued_result(result_queue) # pops t's result from the queue;
# waits until step t-1's data has been
# copied to host and then processes result
4. Deferred bonus token
In our V1 engine, we dealt with the bonus token by running $K+1$ forward passes of the draft model and then replacing the $(K+1)$’th token with the bonus token generated by the target model. We do this so that the draft’s KV cache for the $K$’th token is already computed for the next SMC-SD round. The single uncommitted “frontier token” is then the bonus token.
In our v0.2.0 engine, we defer running a forward pass of the draft model on the $K$’th token until the first autoregressive draft generation of the next SMC-SD cycle, where it is processed in parallel with the bonus token. For a $N=8$/batch-size-1 configuration, the arithmetic intensity of this two-uncommitted-token forward pass increases to $\approx 16$, which is still far less than the roofline arithmetic intensity of most GPUs, so it can safely be run in approximately the time as if it were run with 1 uncommitted token.
In code, the SMC-SD V1 draft and verify phases looked like this:
def draft_forward(self):
for i in range(self.K+1): # loop iterates K + 1 times
self.out_tokens[i] = self._sample_draft_token(self.batch)
def verify(self, draft_tokens):
bonus_token = self._sample_verify_token(self.out_tokens[:self.K])
self.out_tokens[self.K] = bonus_token # the bonus token slot gets overwritten
In our SMC-SD v0.2.0 engine, the draft phase looks like this:
def draft_forward(self):
out_tokens[0] = self._sample_draft_head_token(self.batch) # two-token draft-forward
for i in range(1, self.K): # loop iterates K times
out_tokens[i] = self._sample_draft_token(self.batch) # single-token draft-forward
def verify(self, draft_tokens):
bonus_token = self._sample_verify_token(out_tokens[:self.K])
out_tokens[self.K] = bonus_token
For a $K=1,N=64$, Llama-1B/8B configuration on an H100, our profiler timeline looks like this:
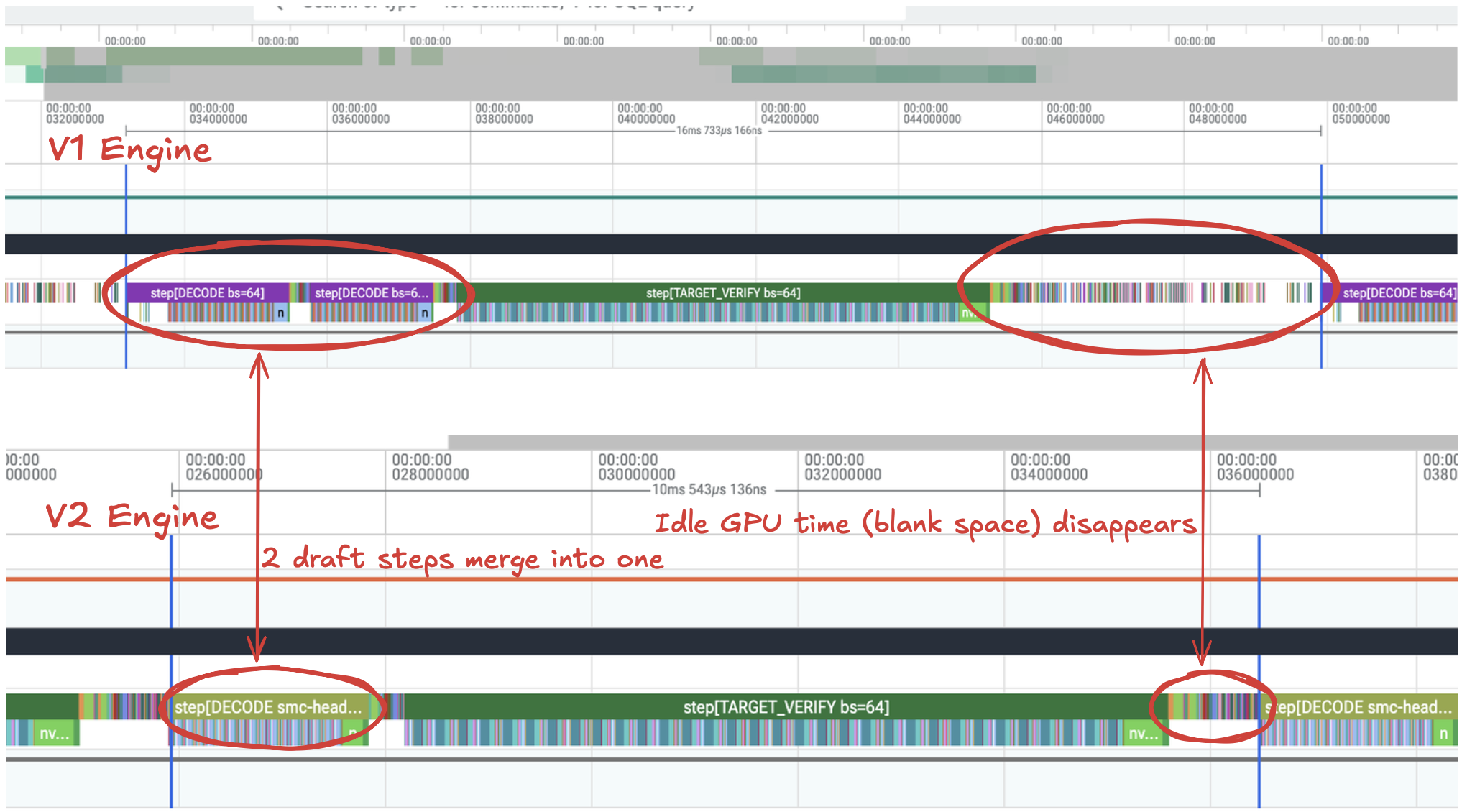
Idle GPU time between SMC-SD steps effectively disappears we go from 122 tokens-per-second to 190—-a 59% speed-up!
5. Cuda-graphing the full cycle
Per cycle, the draft model runs $K$ autoregressive forward passes. In the straightforward implementation, each of those are its own decode-graph replay, its own replay_prepare to write attention metadata, its own kernel launches for the forward and the eager (op-by-op) sampling. The sampled token stays on the GPU and flows straight into the next forward, so there’s no synchronization here — but every step still costs host time to dispatch. At ~0.74 ms of host dispatch per step, and with the draft model’s per-step GPU work being small, the GPU drains its kernel queue faster than the CPU can refill it and ends up launch-bound — about 25% idle at batch size 32, waiting on the CPU rather than on a sync.
The fix is to capture the entire draft phase, all $K$ forwards and the sampling between them, as a single CUDA graph per batch-size bucket. One replay() then runs the whole chain with zero host dispatch in the middle:
for s in 0..K:
logits = draft_model(input_ids, positions, attn_backends[s])
token = argmax(logits/T + Gumbel) # sampling, in-graph
input_ids <- token; positions += 1
Interestingly, SMC-SD is an easier case to do this for than normal speculation. The whole thing works because batch composition is static within a cycle, the draft loop and the verify pass that follows see the same batch size, particle slots don’t move mid-cycle, and the per-step seq_lens are just affine in the step index. There’s no tree to prune or variable acceptance length to branch on. So the chain of forwards is a fixed shape we can compile into a cuda graph.
5.1 Making the sampler capturable: Gumbel-max
To capture the draft phase as one graph, the sampling has to live inside the graph too. The obvious sampler, softmax(logits/T) → torch.multinomial, cannot be captured: its RNG isn’t graph-safe.
This is where the Gumbel-max trick comes in. The identity
\[\arg\max_i\big(\text{logits}_i/T + g_i\big),\quad g_i \sim \text{Gumbel}(0,1)\quad\equiv\quad \text{sample from } \text{softmax}(\text{logits}/T)\]turns a categorical draw into an elementwise add followed by an argmax . The Gumbel noise comes from torch.rand_like, which under graph capture uses CUDA’s graph-safe Philox RNG, so every replay() draws fresh randomness instead of replaying one frozen sample. That’s exactly the property multinomial lacks, and it’s what unlocks the whole capture.
In code, the captured draft loop is:
for s in range(num_steps): # all K forwards, captured once
logits = forward(input_ids, positions, fb).next_token_logits
scaled = logits / self.temperature
gumbel = -torch.log(-torch.log(torch.rand_like(scaled).clamp_min_(tiny)))
idx = torch.argmax(scaled + gumbel, dim=-1) # graph-safe categorical draw
tokens_out[:, s + 1] = idx
if s < self.K: # draft log-prob, fused
chosen = scaled.gather(1, idx.unsqueeze(1)).squeeze(1)
logprobs_out[:, s] = chosen - torch.logsumexp(scaled, dim=-1)
input_ids.copy_(idx); positions.add_(1)
A nice bonus falls out of this. SMC needs each draft token’s log-prob for the importance-weight update, and here it’s computed inline from the same scaled tensor as chosen − logsumexp(scaled) , so no separate log_softmax → exp → gather pass. The sample and its log-prob share one read of the logits.
Once sampling is in-graph, there’s no reason to stop at the draft phase. Because the batch shape is static across the entire cycle, we can extend the capture through the TARGET_VERIFY forward on the score model, the per-position weight diff (score_logprob − draft_logprob), and the Gumbel-max bonus draw, which samples from the same tempered-power target p_T^α as the per-step draws, so the whole cycle runs off one consistent, capturable sampler. One replay() then covers everything the worker does between “batch prepared” and “result tensors ready.” The deferred-bonus two-token head from the previous section folds into the same capture.
Citing
@misc{emara2026_smcsd_engine_v2,
title={SMC-SD Inference Engine v0.2.0},
author={Yahya Emara and Mauricio Barba da Costa and Chi-Chih Chang and Mohamed Abdelfattah},
year={2026},
url={https://abdelfattah-lab.github.io/blog/smcsd_engine_v0_2_0},
}