

SMC-SD Inference Engine v0.1.0




1. Introduction
Speculative decoding speeds up LLM generation by using a small draft model to guess several tokens and having a large target model check them in one pass. It works well when the draft guesses correctly, but every time the draft is wrong, those tokens are thrown away and the work is wasted. SMC (Sequential Monte Carlo speculative decoding) takes a different approach. Instead of running one sequence and rejecting bad guesses, it runs N sequences in parallel, called particles, that all start from the same prompt. A small draft model proposes tokens and a larger target model scores them, and rather than accepting or rejecting specific tokens, SMC reweighs the particles by how well the target agrees with the draft. Each round extends every particle by K+1 tokens: K from the draft plus one bonus token sampled from the target. When a few particles end up holding most of the weight, the population is resampled in proportion to those weights, so strong particles are copied and weak ones are dropped to ensure a bounded gap to the target distribution.
particles = [prompt] * N # N particles, same prompt
while not all_finished(particles):
extend(particles, K) # draft model: +K tokens each
w = target.score(particles) # weight each particle (target vs draft)
append_bonus(particles) # +1 bonus token (sampled from target) → K+1 / round
if ESS(w) < threshold * N:
particles = resample(particles, w) # ∝ weight; reset row weights
Please refer to our paper for more details on the algorithm, and for extensive experimentation. In the following sections, we describe the core engineering problem and the solutions when implementing SMC-SD within a high-performance inference server. Our implementation realizes SMC’s potential to reach a 5.2x speedup over autoregressive decoding.
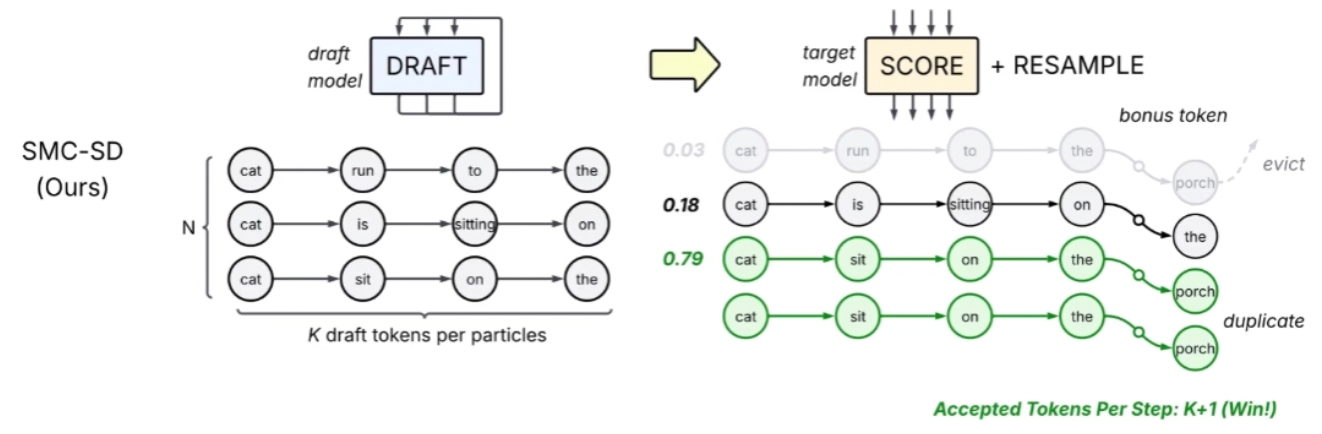
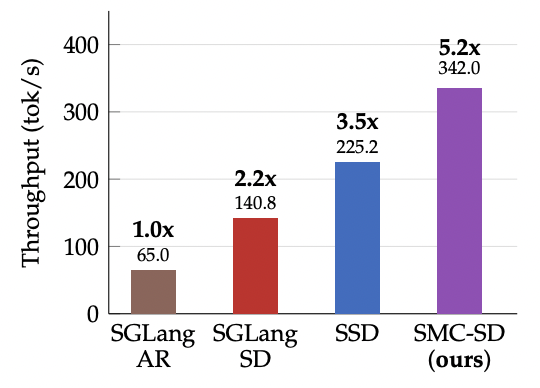
2. The engineering challenge of supporting SMC-SD
In SMC-SD, a single user request no longer owns an independent decoding sequence. After prefill, a request fans out into $N$ particle sequences that share the same prompt, decode in parallel, carry different weights (i.e., a log-probability difference), and can be resampled into one another. This breaks a common assumption in existing LLM serving systems: a request is usually treated as one active sequence throughout decoding.
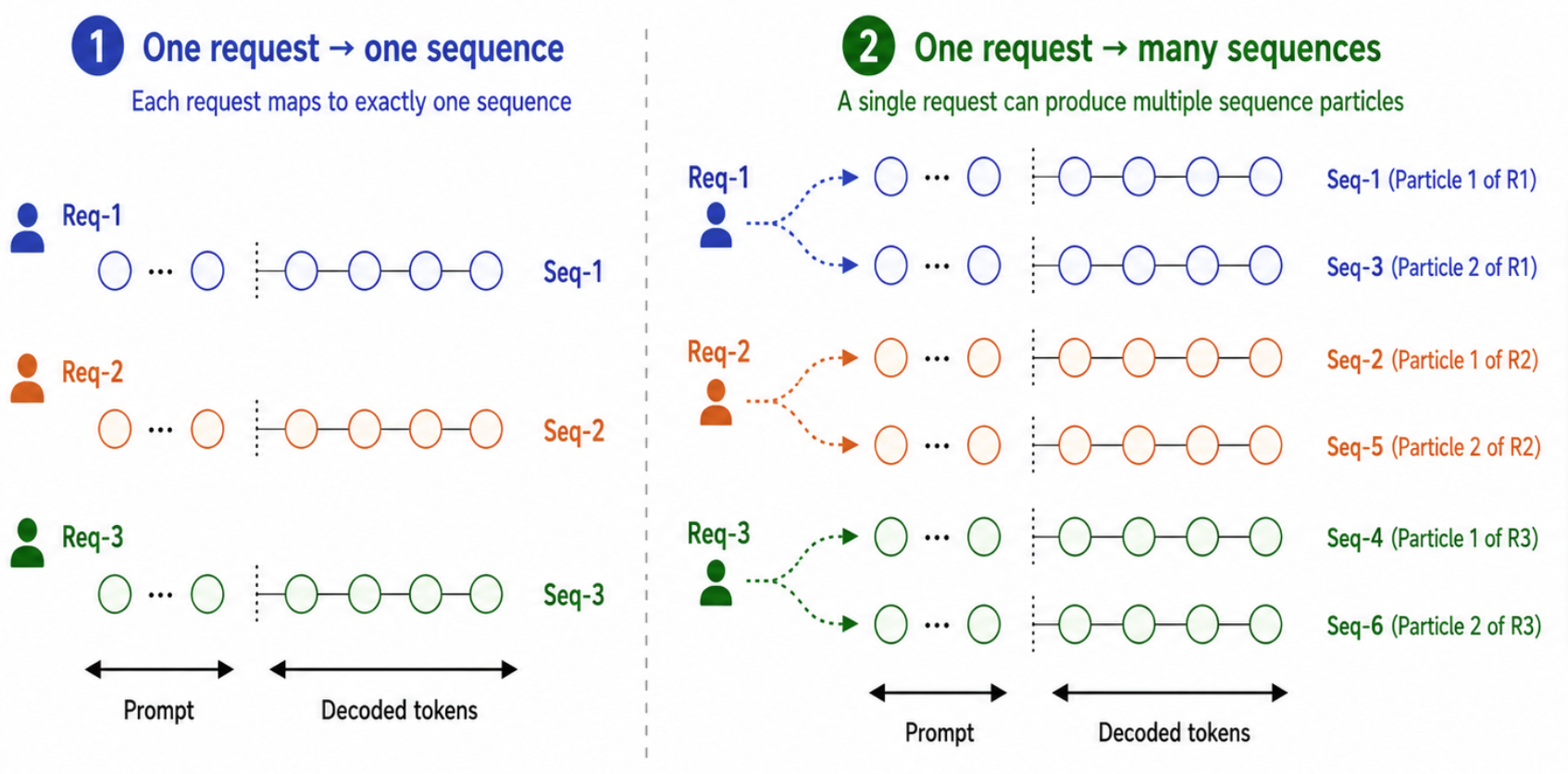
However, this does not mean the entire engine has to be rewritten. Most serving engines (such as SGLang and vLLM) are composed two layers: the scheduler and the worker, as illustrated below. The scheduler maintains the request lifecycle. It accepts requests, tracks their states, organizes runnable work into batches, prepares device tensors ready for processing, and determines when requests are finished. The worker is the execution layer: given a batch of sequences, it performs one model-forward iteration and returns the decoding outputs, such as logits or sampled tokens. It is not responsible for request lifecycle control.
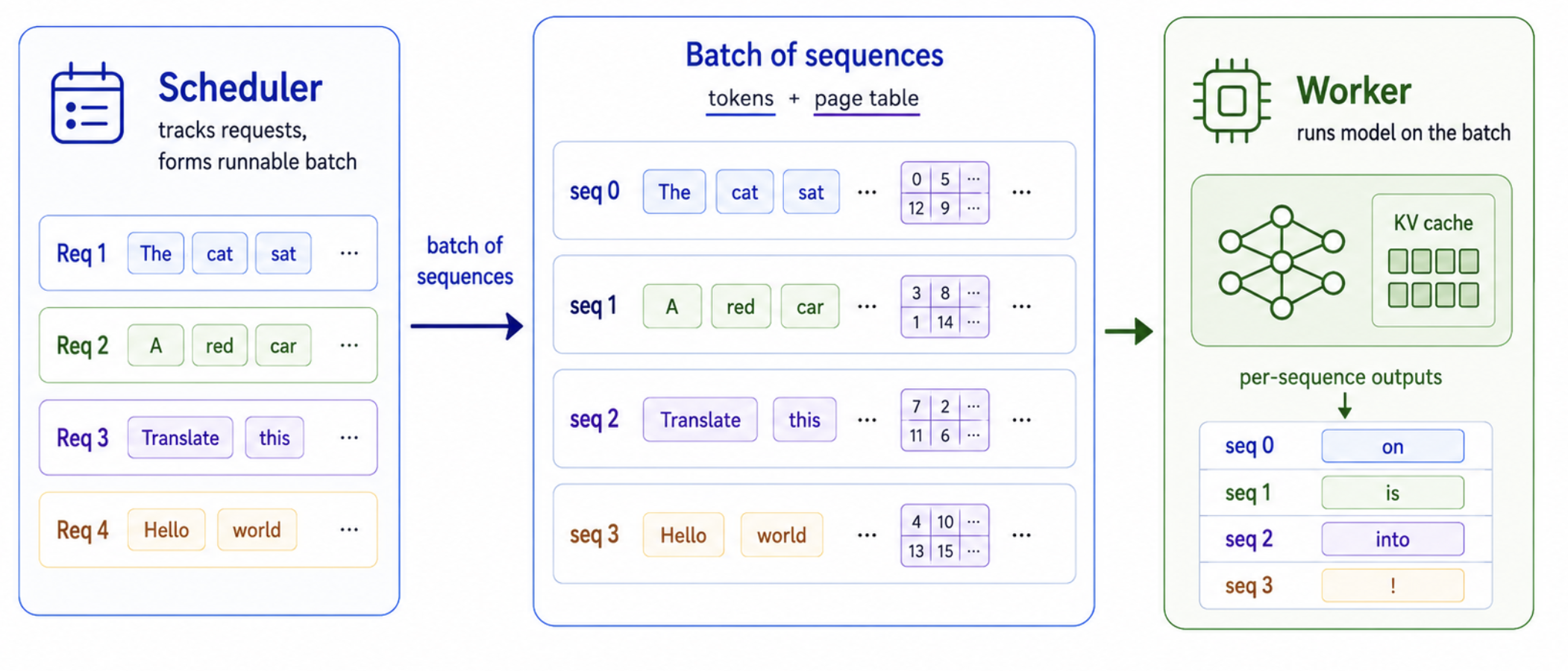
This separation is the key observation and rationale for building our SMC-SD engine. Although an SMC-SD request consists of $N$ coupled particles, the worker does not need to know whether two sequences came from different user requests or from two particles in the same SMC group. From the worker’s point of view, they are simply sequences in a flat batch. Group ownership, particle weights, ESS checks, resampling, and finalization are all lifecycle concerns, so they belong in the scheduler.
This clean boundary allows us to leave most of SGLang’s worker path alone. The worker can keep using the existing model-forward path, including its model runner, CUDA graph capture, fused kernels, and model-specific optimizations. At execution time, each particle is still just an ordinary sequence row. With that boundary marked, the implementation task becomes much clearer. The new work is mainly concentrated above the worker: we need an SMC-aware scheduler that manages request fan-out, particle groups, resampling, and group-level finalization while still presenting the worker with the same flat sequence batch it already expects.
3. The SMC-SD scheduler design
With this worker-scheduler boundary in place, the rest of the design is scheduler state management. The scheduler has to keep one request as a particle group, store particle state across decode rounds, resample particles in place, and finally collapse the group back into one response.
3.1 Request lifecycle
In ordinary decoding, a request enters the scheduler as one sequence, keeps decoding as that sequence, and leaves when the sequence finishes. SMC-SD adds one extra transition: after prefill, the request fans out into $N$ particle sequences that must stay tied together until the request is complete.
In our scheduler, one request follows this lifecycle:
admit parent sequence
→ prefill parent once
→ create N particle sequences
→ decode and resample the particles together
→ choose one final response
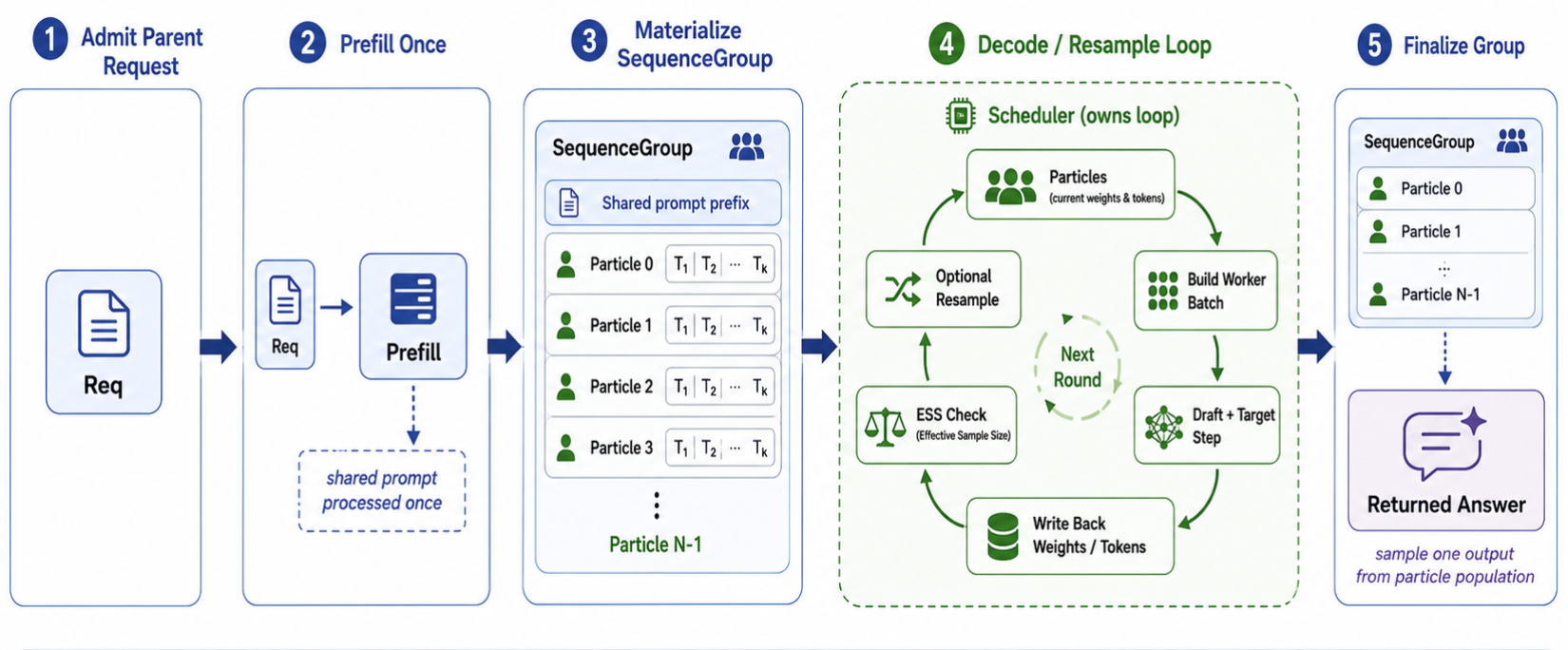
We represent this lifecycle with a SequenceGroup. Before fan-out, the group contains only the parent sequence. After fan-out, it owns the $N$ particle sequences cloned from that parent.
@dataclass
class SequenceGroup:
parent_seq: Sequence
n_particles: int
particle_seqs: Dict[int, Sequence] = field(default_factory=dict)
The purpose of SequenceGroup is to give the scheduler one object for the whole request, even though the request later runs as many particle sequences. The scheduler first prefills the parent sequence once, then creates $N$ particles from that prefilled parent. This avoids processing the shared prompt $N$ times.
After that, the request stays group-owned. The particles decode together, resample together, and are finalized together. A single particle may finish early, but the user request is not complete until the group is complete. In the actual SGLang implementation, these sequences are backed by Req objects, but the scheduler-level idea is simply: one parent sequence becomes $N$ particle sequences under one group.
3.2 “ScheduleBatchSMC”: persistent slots for particle state
The scheduler also has to feed the model worker. In SGLang, the worker-facing object is a ModelWorkerBatch; the scheduler does not keep that object as its source of truth. Instead, ordinary decoding maintains a live ScheduleBatch, then projects that scheduler state into ModelWorkerBatch when the worker is ready.
A simplified ScheduleBatch is a dense struct-of-arrays over running requests:
class ScheduleBatch:
reqs: List[Req] # [ReqA, ReqB]
seq_lens: torch.Tensor # [5, 7]
req_pool_indices: torch.Tensor
def filter_batch(self, keep):
self.reqs = [self.reqs[i] for i in keep]
self.seq_lens = self.seq_lens[keep]
self.req_pool_indices = self.req_pool_indices[keep]
This layout works for ordinary autoregressive decoding. A ScheduleBatch row is the current dense position for reqs[i], and the aligned tensors use the same order. Repacking is acceptable because membership changes only when requests enter or leave.
SMC-SD breaks the invariant behind that layout: a row can no longer be removed just because the particle currently stored there has finished. A particle that emits EOS is still part of its group’s population until the whole group finalizes. It may remain as a completed candidate, or it may later be overwritten by resampling. Membership and liveness are no longer the same thing.
For that reason, we introduce ScheduleBatchSMC as a scheduler-owned persistent slot buffer. When a group fans out, it claims $N$ slots. Those slot addresses stay stable until the group is finalized. Group ownership stays fixed, while the particle state inside each slot can grow, finish, or be replaced by resampling.
class ScheduleBatchSMC:
# Persistent tensors, indexed by slot id.
seq_lens: torch.Tensor # [max_slots]
kv_allocated_lens: torch.Tensor # [max_slots]
req_pool_indices: torch.Tensor # [max_slots]
finished_mask: torch.Tensor # [max_slots]
finished_len: torch.Tensor # [max_slots]
all_token_ids: torch.Tensor # [max_slots, max_output_len]
log_weights: torch.Tensor # [max_slots]
interval_weights: torch.Tensor # [max_slots]
verified_ids: torch.Tensor # [max_slots]
prev_last_draft_ids: torch.Tensor # [max_slots]
# Group ownership.
group_slot_lists: Dict[str, List[int]] # CPU: group_id -> slots
group_to_slots: torch.Tensor # GPU: [max_groups, N]
row_in_use: torch.Tensor # GPU: [max_groups]
# Projection into the worker-facing batch.
active_slots: torch.Tensor # slot ids -> ModelWorkerBatch rows
This creates two views of the same decode state. ScheduleBatchSMC is the scheduler source of truth: it owns group membership, persistent slot ids, per-slot token history, sequence lengths, finished masks, KV metadata, and particle weights. ModelWorkerBatch remains the worker-facing execution format: a dense batch of sequence rows built immediately before a worker step.
The bridge between the two views is active_slots. The scheduler gathers allocated slot ids into contiguous ModelWorkerBatch rows, lets the worker execute, then writes results back into the same persistent slots. In the current implementation, active_slots includes every allocated slot, including finished particles, so an individual particle finishing does not change group membership or force the scheduler to rebuild the group.
3.3 Decode as gather → worker → write back
Once the particle state is stored in persistent slots, every decode round follows the same pattern. The scheduler gathers slot state into a worker batch, the worker runs one SMC-SD model step, and the scheduler writes the result back into the same slots.
persistent slots
→ gather slots into ModelWorkerBatch
→ run draft + target worker step
→ write results back to the same slots
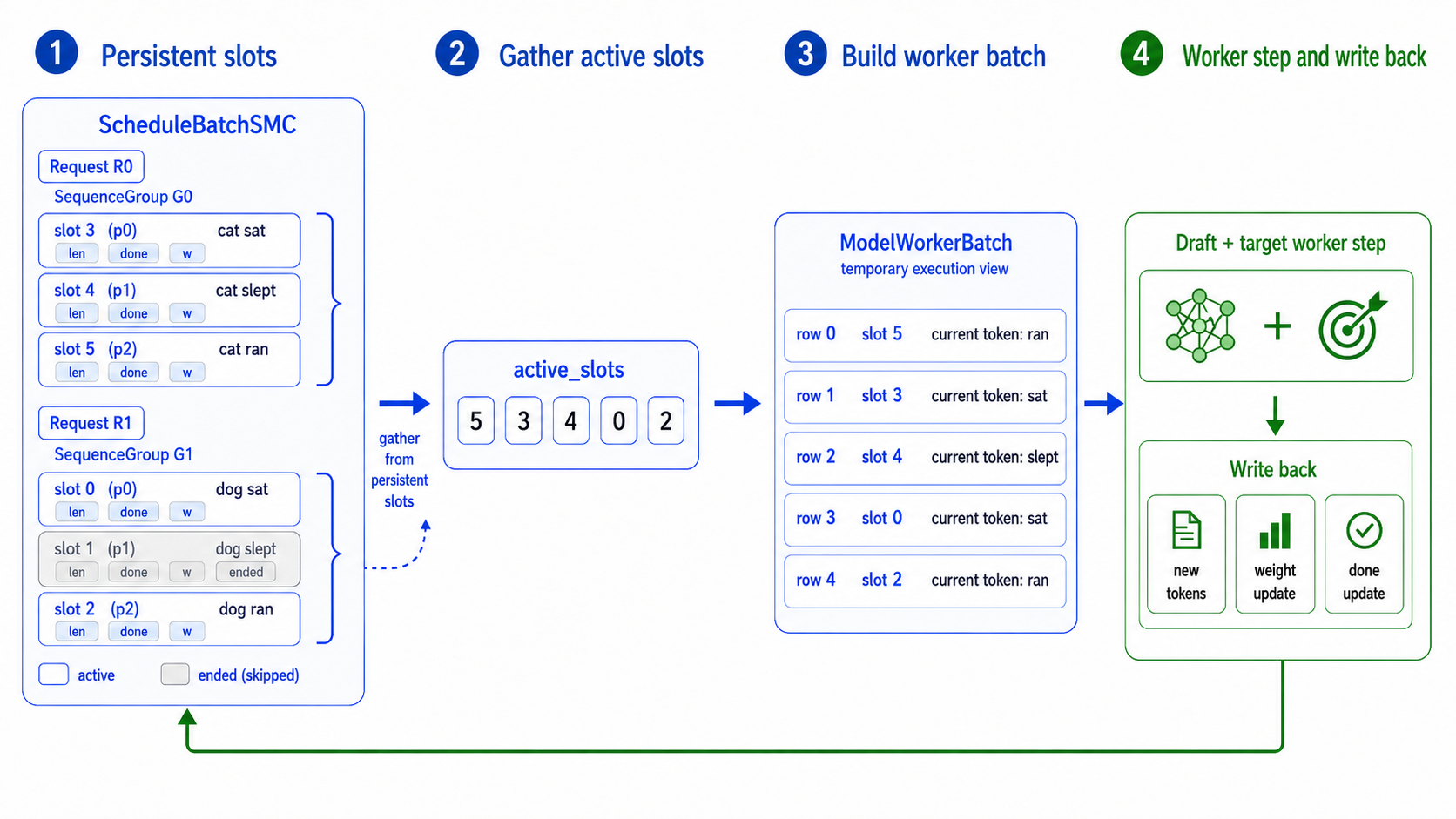
The figure shows two request groups inside ScheduleBatchSMC. Each request owns a SequenceGroup, and each group owns several persistent particle slots. The slot ids are stable within each group, but active_slots can gather them in a different order before building the worker batch.
The example also shows one particle that has already ended. It still appears in ScheduleBatchSMC, because it remains part of the group-owned state, but it is skipped from the worker batch in this simplified illustration. The active slots are gathered into contiguous worker rows:
active_slots = [5, 3, 4, 0, 2]
row 0 → slot 5
row 1 → slot 3
row 2 → slot 4
row 3 → slot 0
row 4 → slot 2
The worker does not need to know that these rows came from two request groups. It only receives a normal ModelWorkerBatch. It runs the draft and target model calls for one SMC-SD round and returns the updates the scheduler needs.
For each particle, the worker produces three kinds of updates:
new tokens # tokens appended to the particle
weight update # how much the particle weight changes
done update # whether the particle reached EOS or the length limit
The scheduler then writes those updates back into the persistent slots. It appends new tokens, updates the particle weights, stores the token needed for the next round, and marks a particle as done if it finished. After that, the next decode round starts again from ScheduleBatchSMC.
3.4 Resampling: In-place slot reassignment
When the particle weights become too uneven, the scheduler resamples: it copies strong particles and drops weak ones so the surviving population reflects the weights. A high-weight particle may be copied into several slots, while a low-weight particle is overwritten.
At the scheduler level, resampling is just a list of copy jobs of the form dst_slot <- src_slot, where each job overwrites the destination slot’s particle with the source slot’s:
1 <- 0 # slots 1 and 2 both take the particle from slot 0
2 <- 0
3 <- 1 # slot 3 takes the particle from slot 1
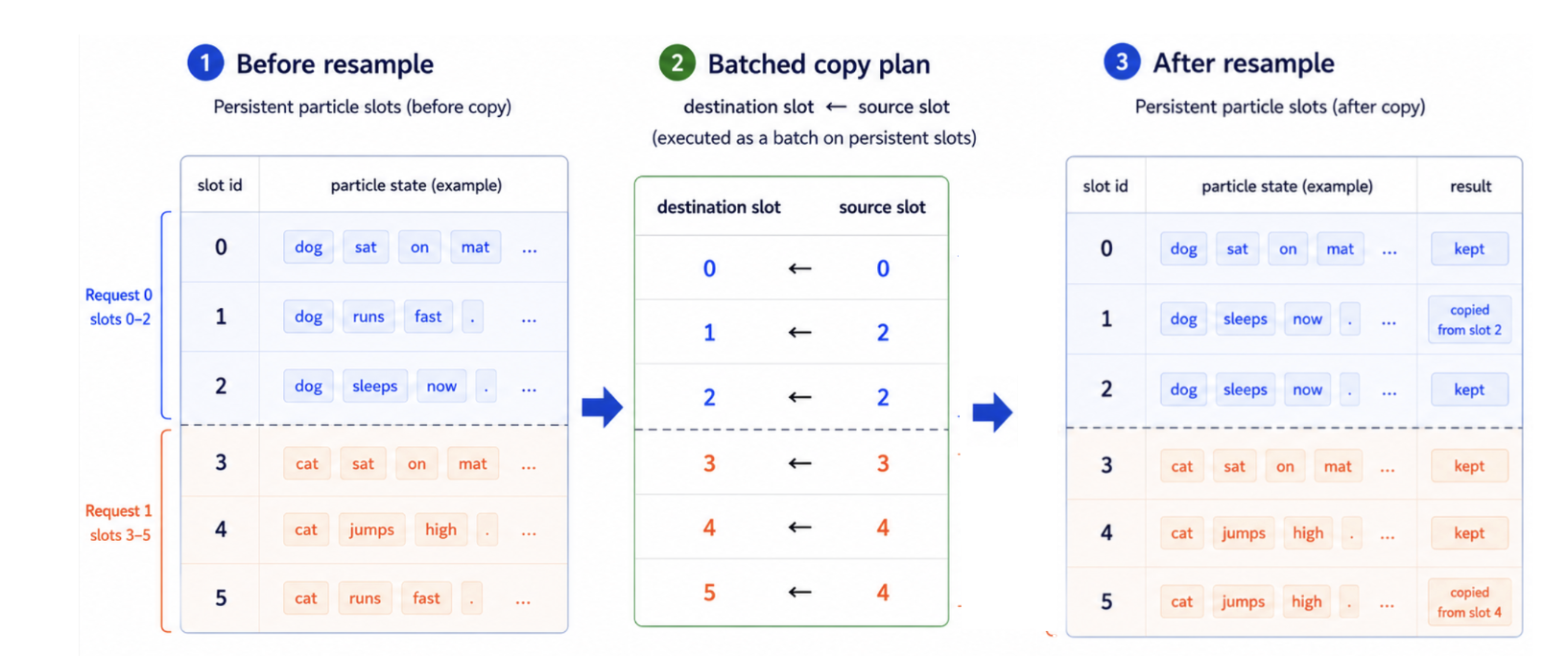
The destination slot keeps its identity and still belongs to the same request group; what changes is only the particle state stored inside it.
For each copy job, the scheduler copies the generated tokens, sequence length, done flag, current weight, the token used to start the next round, and the KV-cache page pointers. The KV part is important: we do not copy raw KV tensors. Because the KV cache is page-based, resampling can copy page pointers and update reference counts. If two slots now share the same prefix, they can point to the same KV pages. Pages that are no longer referenced are released.
So resampling does not rebuild the batch and does not create a new set of requests. It updates particle state inside stable slots.
3.5 Finalization: Returning one response
Inside the scheduler, one request is still running as $N$ particles, but the serving API has to hand back a single response — so there is one last step before the request can leave. A group is ready to finalize once every particle has stopped, either by reaching the end-of-sequence token or by hitting the maximum length. The scheduler then picks one particle to stand in for the whole group, sampling from the final population so that higher-weight particles are more likely to be chosen.
Concretely, for a group with $N$ slots, the scheduler reads each particle’s log-weight, turns the weights into a probability distribution with a softmax, and draws one slot from it. The tokens already sitting in the chosen slot become the parent sequence’s output, so there is nothing left to decode:
slots = group_to_slots[group_row] # [N]
group_log_weights = log_weights[slots] # [N]
probs = torch.softmax(group_log_weights, dim=0)
picked_slot = slots[torch.multinomial(probs, num_samples=1)]
output = all_token_ids[picked_slot, :finished_len[picked_slot]]
With the output in hand, the request is complete. The scheduler then frees the group’s slots so future requests can reuse them.
4. Conclusion
SMC-SD breaks the “one request = one sequence” assumption, turning each request into a group of coupled particles that fan out, decode in parallel, and resample into one another. The key insight in this v1 design is that this complexity remains above the worker/scheduler boundary: group ownership, weights, ESS checks, resampling, and finalization all live in the scheduler, so the worker continues to see an ordinary flat batch, and we reuse SGLang’s existing forward path largely unchanged. In the upcoming blog post, we will share more details on lower-level optimizations around the SMC scheduler that we did to squeeze the performance, such as a customized CUDA graph and KV-Cache management tailored for SMC. Stay tuned for more details!
Citing
@misc{chang2026_smcsd_engine_v1,
title={SMC-SD Inference Engine v0.1.0},
author={Chi-Chih Chang and Yahya Emara and Mauricio Barba da Costa and Mohamed Abdelfattah},
year={2026},
url={https://abdelfattah-lab.github.io/blog/smcsd_engine_v0_1_0},
}