

RaZeR: Pushing the Limits of NVFP4 Quantization with Redundant Zero Remapping




 Wonsuk Jang
Stanford
Wonsuk Jang
Stanford
Yuheng Wu
Stanford
Thierry Tambe
Stanford
Jae-sun Seo
Cornell

arxiv: 2501.04052
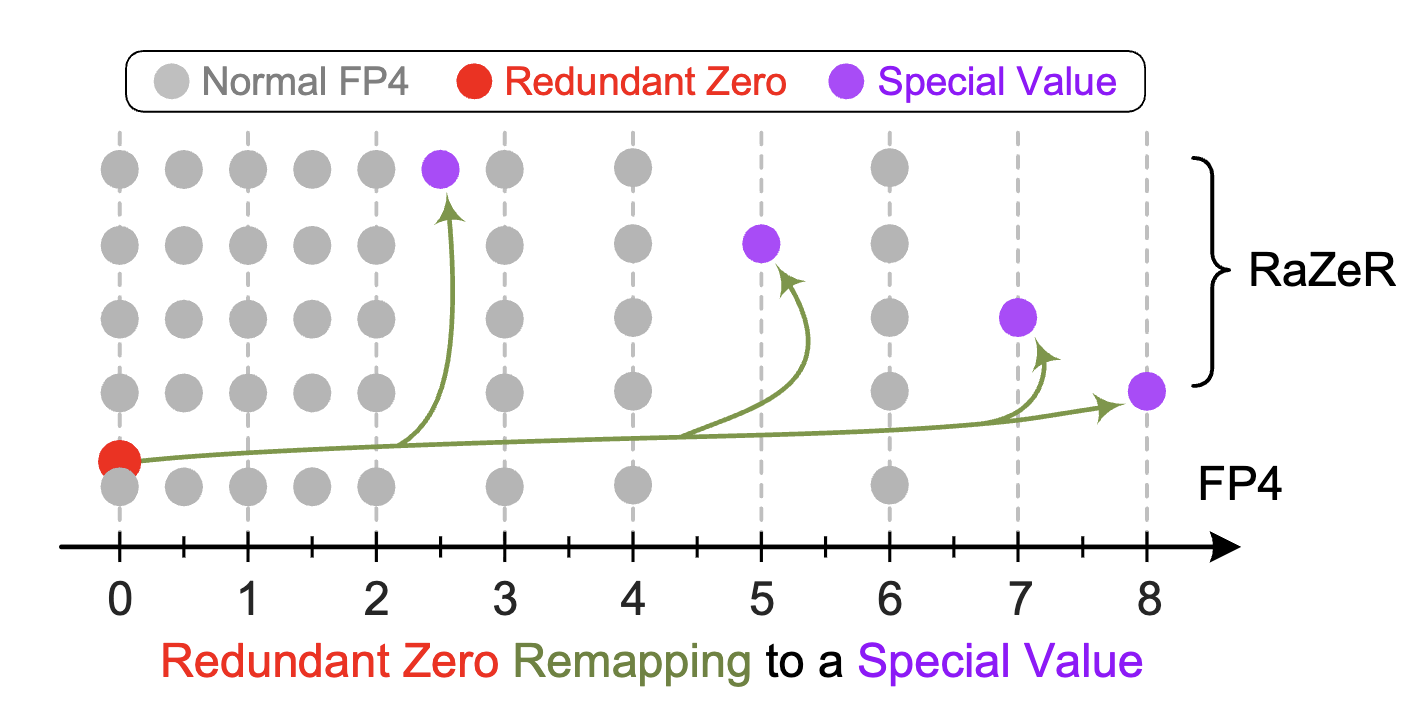
Abstract
The recently introduced NVFP4 format demonstrates remarkable performance and memory benefits for quantized large language model (LLM) inference. However, we observe two types of redundancy in NVFP4 encoding: (1) The FP4 element format naturally exposes an unused quantization value due to its sign-magnitude representation that contains both positive and negative zeros. (2) The FP8 block scaling factor has an unused sign bit because it is always positive. Additionally, we find that LLM weights are more tolerant to a lower-precision block scaling factor. Based on these observations, we propose Redundant Zero Remapping (RaZeR), an enhanced numerical format that pushes the limits of NVFP4 for more accurate LLM quantization under the same memory footprint. RaZeR leverages the redundant bits of the block scaling factor to adaptively remap the redundant FP4 zero to additional quantization values with improved accuracy. To demonstrate the practicality of RaZeR, we design efficient GPU kernels for RaZeR-quantized LLM inference and propose novel hardware to natively support this. Extensive experiments validate RaZeR’s superior performance for 4-bit LLM quantization. For example, relative to native NVFP4, RaZeR reduces the average perplexity loss by 34.6% and 31.2% under weight-only and weight-activation quantization, respectively. Code is available at: https://github.com/yc2367/NVFP4-RaZeR.