

Bit-serial Acceleration of LLM Inference with Mixture-of-Datatype Quantization



 Yang Wang
Microsoft
Yang Wang
Microsoft

George Constantinides
Imperial

IEEE Transactions on Computers, 2026
Abstract
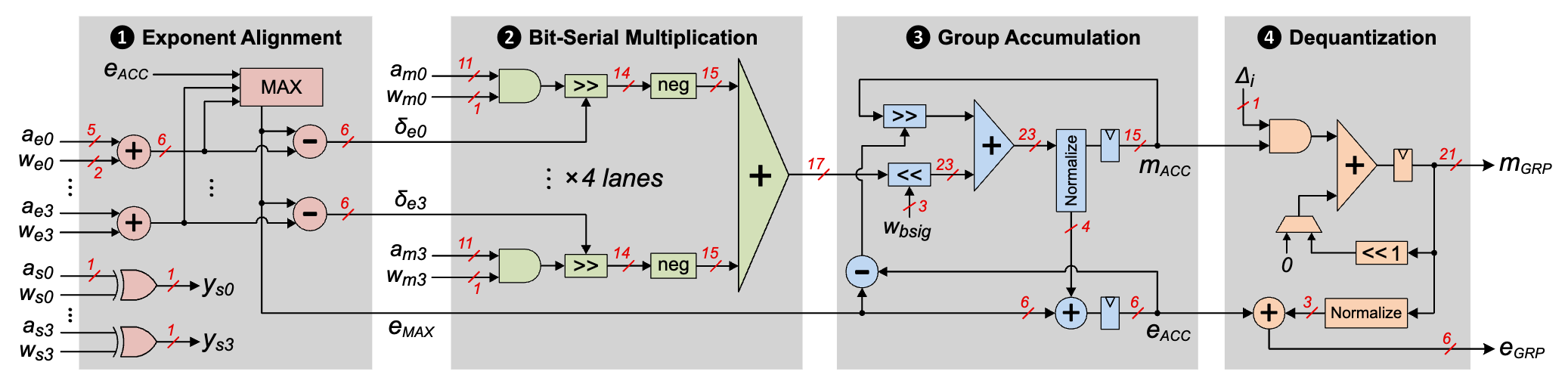
Large language models (LLMs) have achieved significant breakthroughs on machine learning tasks. Yet the substantial memory footprint of LLMs significantly hinders their wide deployment. In this paper, we propose BitMoD, an algorithm-hardware co-design solution for efficient LLM deployment. On the algorithm side, BitMoD introduces “fine-grained data type adaptation”, which uses a different data type to quantize a group (e.g., 128) of weights and key-value-cache (KV-cache). Through the careful design of these data types, BitMoD is able to quantize LLM weights and KV-cache to sub-4-bit precision while maintaining high accuracy. On the hardware side, BitMoD employs the bit-serial computing to easily support multiple numerical precisions and data types, thus providing a flexible trade-off between model accuracy and hardware efficiency. Furthermore, we design low-cost hardware components to effectively handle online KV-cache quantization and per-group partial sum dequantization. Our evaluation on a diverse set of LLMs demonstrates that BitMoD significantly outperforms state-of-the-art LLM quantization methods on both discriminative and generative tasks. Combining the superior model performance with an efficient accelerator design, BitMoD surpasses the state-of-the-art LLM accelerator in terms of both hardware performance and energy efficiency.