

Accelerating Large-Scale Reasoning Model Inference with Sparse Self-Speculative Decoding
 Yilong Zhao
UC Berkeley
Yilong Zhao
UC Berkeley
Jiaming Tang
MIT
Kan Zhu
U Washington
Zihao Ye
Nvidia

Chaofan Lin
Tsinghua
Jongseok Park
UC Berkeley
Guangxuan Xiao
MIT

Mingyu Gao
Tsinghua
Baris Kasikci
U Washington
Song Han
MIT
Ion Stoica
UC Berkeley
International Conference on Machine Learning and Systems, 2026
Abstract
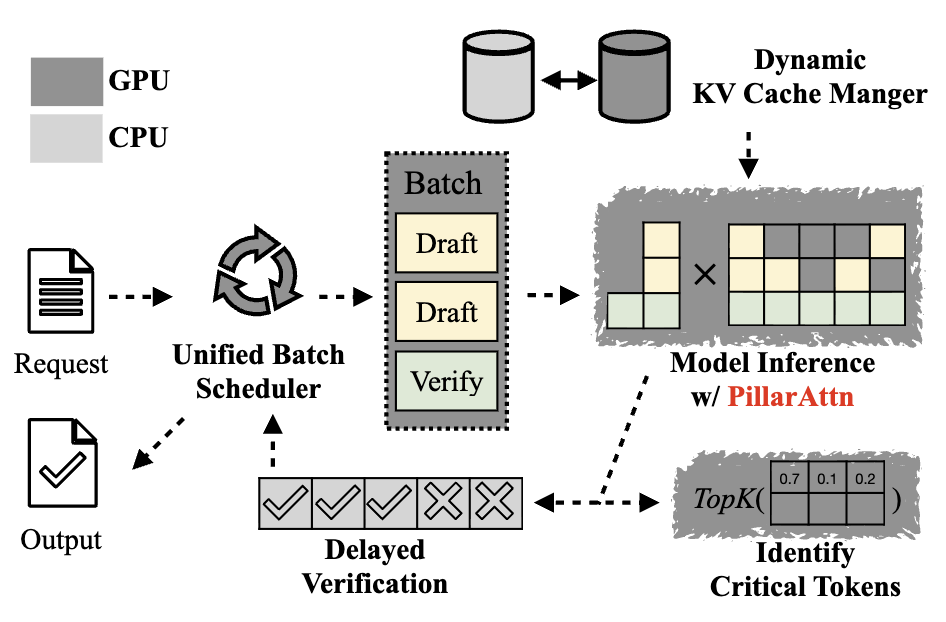
Reasoning language models have demonstrated remarkable capabilities on challenging tasks by generating elaborate chain-of-thought (CoT) solutions. However, such lengthy generation shifts the inference bottleneck from compute-bound to memory-bound. To generate each token, the model applies full attention to all previously generated tokens, requiring memory access to an increasingly large KV-Cache. Consequently, longer generations demand more memory access for every step, leading to substantial pressure on memory bandwidth. To address this, we introduce SparseSpec, a speculative decoding framework that reuses the same model as the draft and target models (i.e., self-speculation). SparseSpec features a novel sparse attention mechanism, PillarAttn, as the draft model, which accurately selects critical tokens via elegantly reusing information from the verification stage. Furthermore, SparseSpec co-designs self-speculation with three system innovations: (1) a unified scheduler to batch token drafting and verification, (2) delayed verification for CPU/GPU overlap, and (3) dynamic KV-Cache management to maximize memory utilization. Across various models and datasets, SparseSpec outperforms state-of-the-art solutions, with an up to 2.13x throughput speedup.