

Rethinking Prefix Caching for Hybrid LLMs




Introduction
Modern LLM applications are pushing toward longer context windows. Few-shot prompting, chain-of-thought reasoning, and retrieval-augmented generation all rely on feeding more context into the model.
As context length grows, the cost of prefill phase quickly adds up, making inference significantly more expensive.
Prefix caching has therefore become a core optimization in serving systems like vLLM and SGLang. The idea is simple: if two requests share the same prefix, we reuse previously computed states instead of recomputing them.
For attention-based models, this works really well. KV cache is stored per token, so systems can reuse partial prefixes. Even if two requests only overlap halfway, you still get meaningful savings.
But Hybrid models complicates prefix reuse. Modern model architectures are increasingly hybrid - they mix attention layers with recurrent components (like state space models) to reduce compute and memory cost.
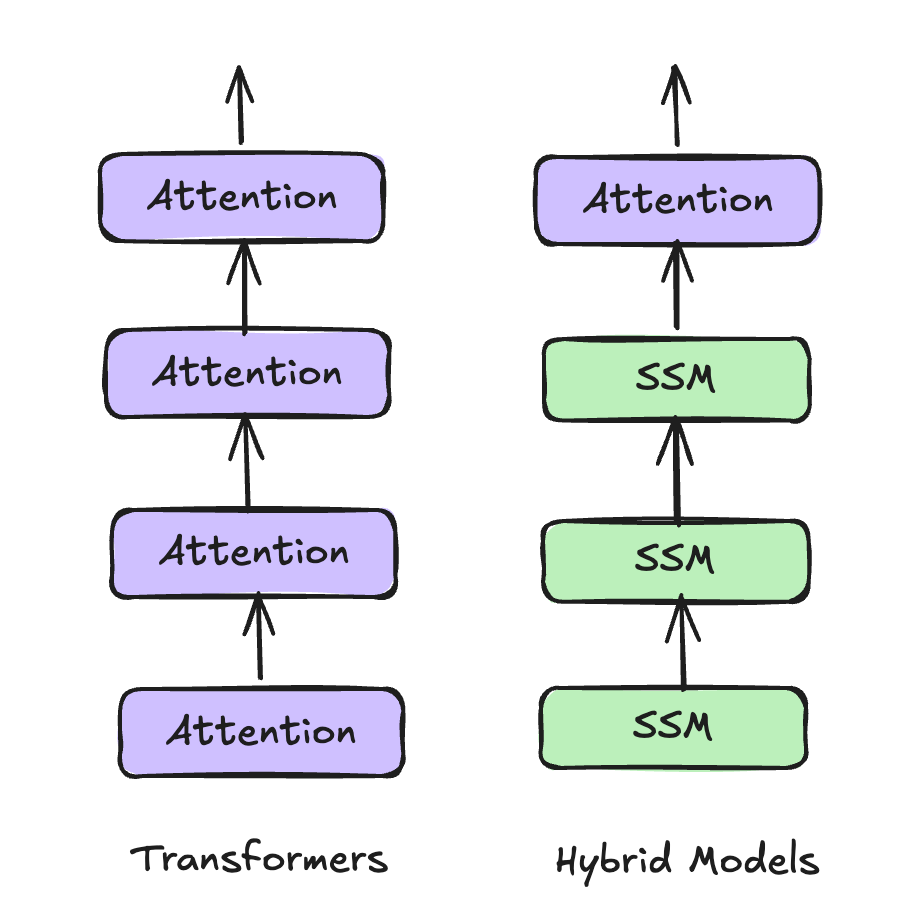
Transformer vs Hybrid model architecture
| Property | Attention | SSM |
|---|---|---|
| Computational Complexity | $O(L^2)$ | $O(L)$ |
| Inference-Time Memory | $O(L)$ | $O(1)$ |
Complexity comparison between Attention and SSM layers
These recurrent states behave very differently from KV caches. Instead of storing information per token, they compress the entire prefix into a single fixed-size state and update it in place, which means you can’t partially reuse a prefix.
So the question now becomes:
How should prefix caching work for hybrid models?
In this work, we start from the FLOP-aware cache eviction idea from Marconi—a recent approach for hybrid model prefix caching—and try to bring it into a real serving system SGLang. In doing so, we identified several practical considerations, leading us to propose a simpler heuristic approach: SegLen.
SegLen is a lightweight, model-agnostic heuristic that captures the core intuition behind Marconi - but in a much simpler form that’s easier to bring into a real serving system. We implement SegLen in SGLang and evaluate it across a range of workloads and memory settings. Our results show that SegLen delivers strong performance while keeping the system much simpler.
Problem
Prefix caching is well understood for attention-only models. But once we introduce recurrent components, the behavior of the cache changes in important ways.
Recurrent State vs KV Cache
Let’s start with the key differences.
KV cache (attention):
- Stored per token
- Grows linearly with sequence length
- Supports partial reuse
Recurrent state (SSM / Mamba):
- Fixed size regardless of sequence length
- Much larger than a single token’s KV
- Updated in-place
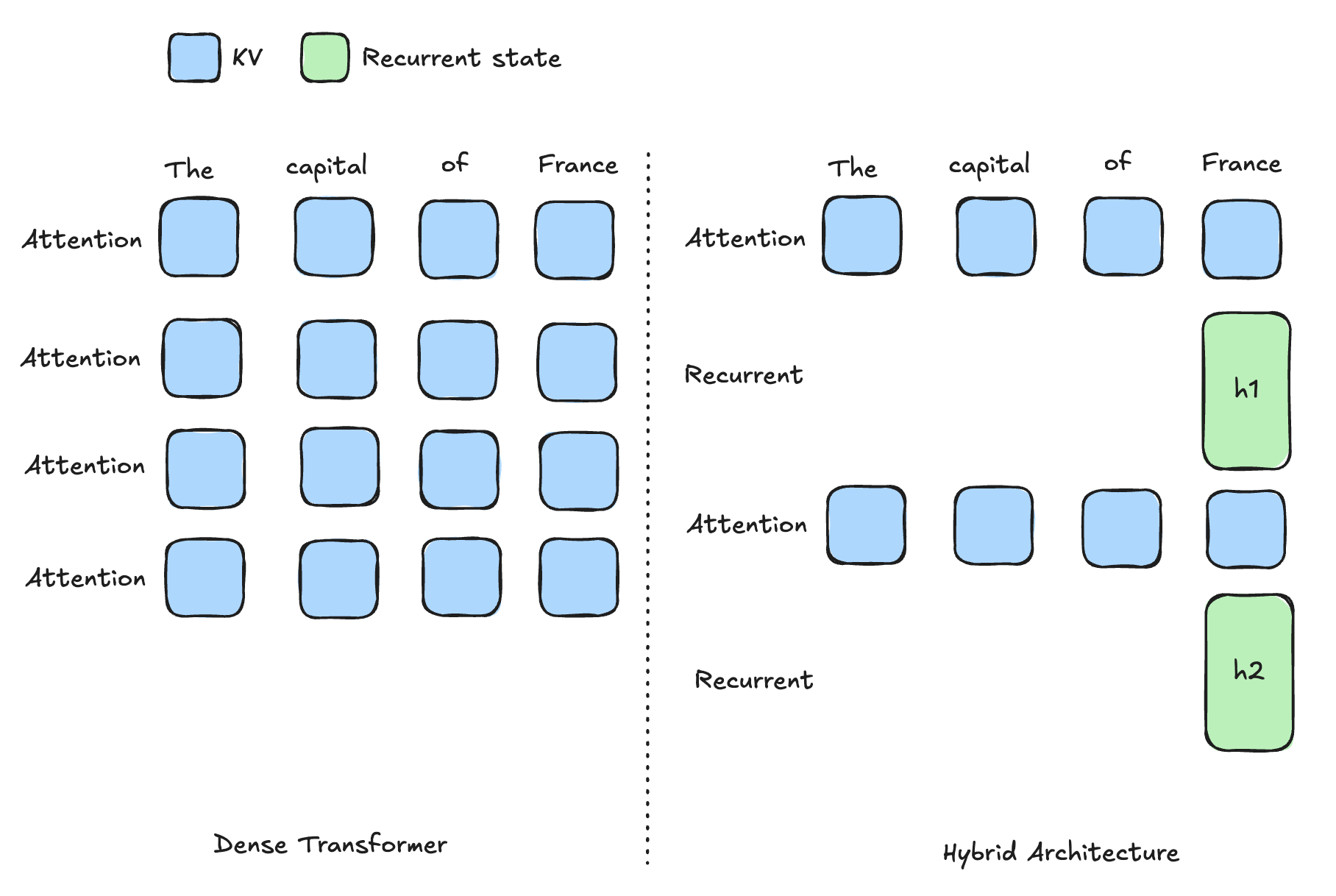
KV Cache vs recurrent state
Because recurrent states are updated in place, you can’t roll them back to represent earlier prefixes.
These differences fundamentally change how prefix reuse works.
Core Problem: All-or-Nothing Reuse
With KV cache, you can reuse any partial prefix.
With recurrent state, reuse becomes all-or-nothing.
To reuse a recurrent state, you need a checkpoint that exactly matches the full prefix of the new request. In practice, this makes reuse much more sparse and much harder to exploit.
Systems Challenge: Big, Sparse, and Expensive Cache
To maximize reuse, one natural idea is to store more checkpoints so we have a better chance of hitting an exact prefix match.
But this quickly creates a new problem.
- Each recurrent state is large
- More checkpoints means more memory usage
- But most checkpoints are still rarely reused
As a result, the cache grows quickly, but the hit rate doesn’t improve much. You end up with a cache that is large, expensive, and sparsely utilized.
So the real question becomes:
how do we decide which cache entries are actually worth keeping?
Marconi: Rethinking Cache Eviction
Marconi proposed a new prefix caching strategy for hybrid models. It starts from a simple observation.
In attention layers, KV cache grows with sequence length. That means longer prefixes take more memory and also save more compute when reused.
Recurrent states behave very differently. They are constant size regardless of sequence length. But the amount of compute they can save depends on how many tokens they represent. So two cache entries can take the same memory, but have very different reuse value.
Size of hybrid model’s cache entries
Key Insight: Flop Aware Cache Eviction
Most systems today rely on simple cache eviction policies like LRU (least recently used), which evict entries based on recency.
But recency alone doesn’t tell us how valuable an entry is.
Marconi proposes a different approach: make eviction decisions based on compute savings.
Each cache entry is scored based on:
- how much compute (FLOPs) it can save if reused
- how much memory it consumes
This leads to the notion of FLOP efficiency — how much compute you save per unit of memory:
\[\text{FLOP-efficiency} = \frac{\text{total FLOPs across layers}}{\text{memory consumption of all states}}\]To combine this with recency, Marconi defines a utility score:
\[s(n) = \mathrm{recency}(n) + \alpha \cdot \mathrm{flop\_efficiency}(n)\]This metric favors cache entries with higher recency, save more compute, and take less memory.
Integrating Marconi into SGLang
We want to bring Marconi into a real serving system by integrating it into SGLang. Before diving into the integration, it’s worth understanding how SGLang handles prefix caching for hybrid models.
SGLang’s Hybrid Cache Management
SGLang implements prefix caching using a radix tree.
Each node in the tree represents a shared prefix segment, and stores:
- the tokens for that segment
- pointers to the cached states
For hybrid models, SGLang extends this structure to manage both KV cache and recurrent state together.
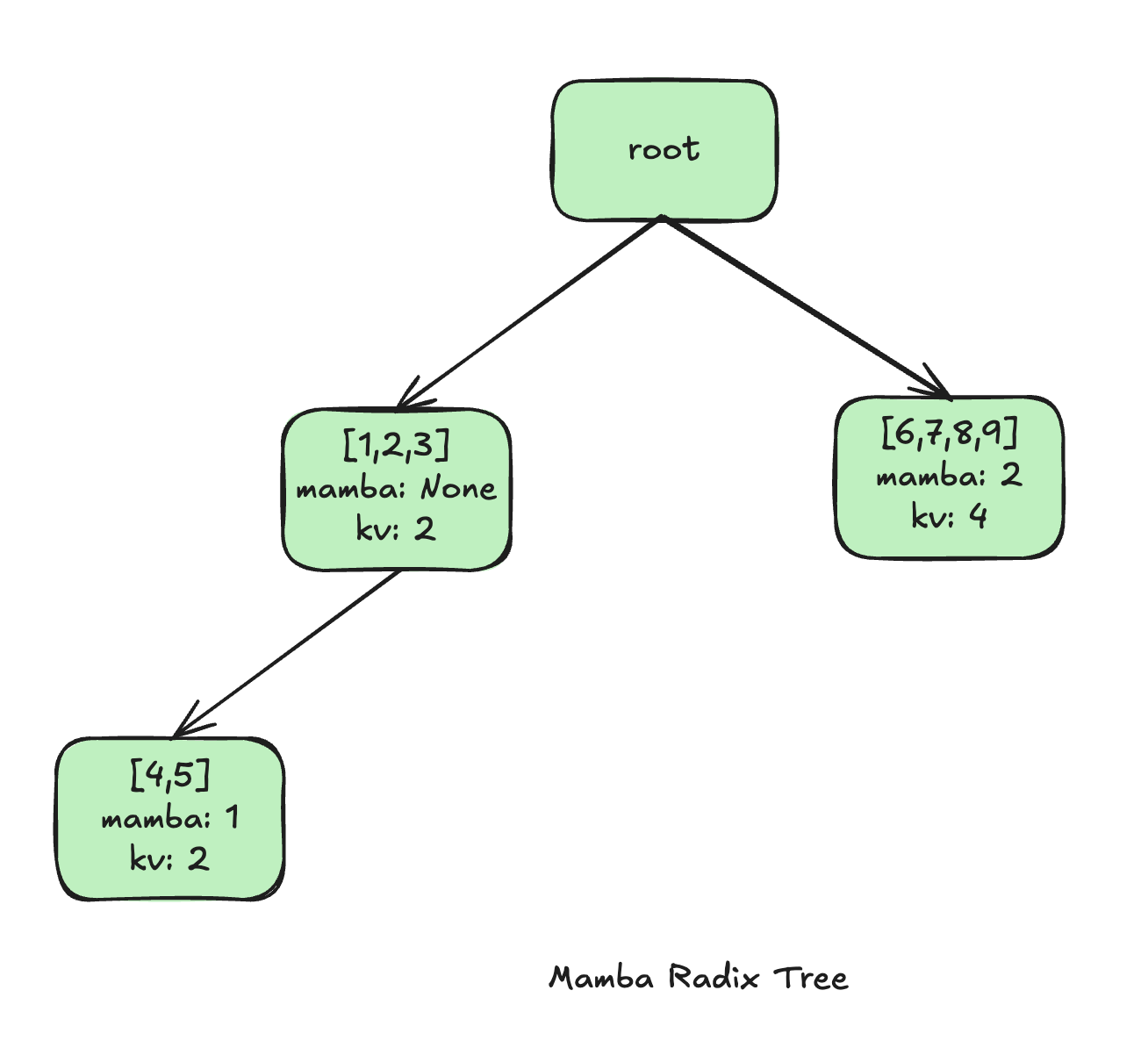
Example of Mamba Radix Tree in SGLang
Under the hood, memory is split into two separate pools:
- KV cache pool (attention)
- Mamba pool (recurrent state)
Each pool has its own allocation and eviction logic.
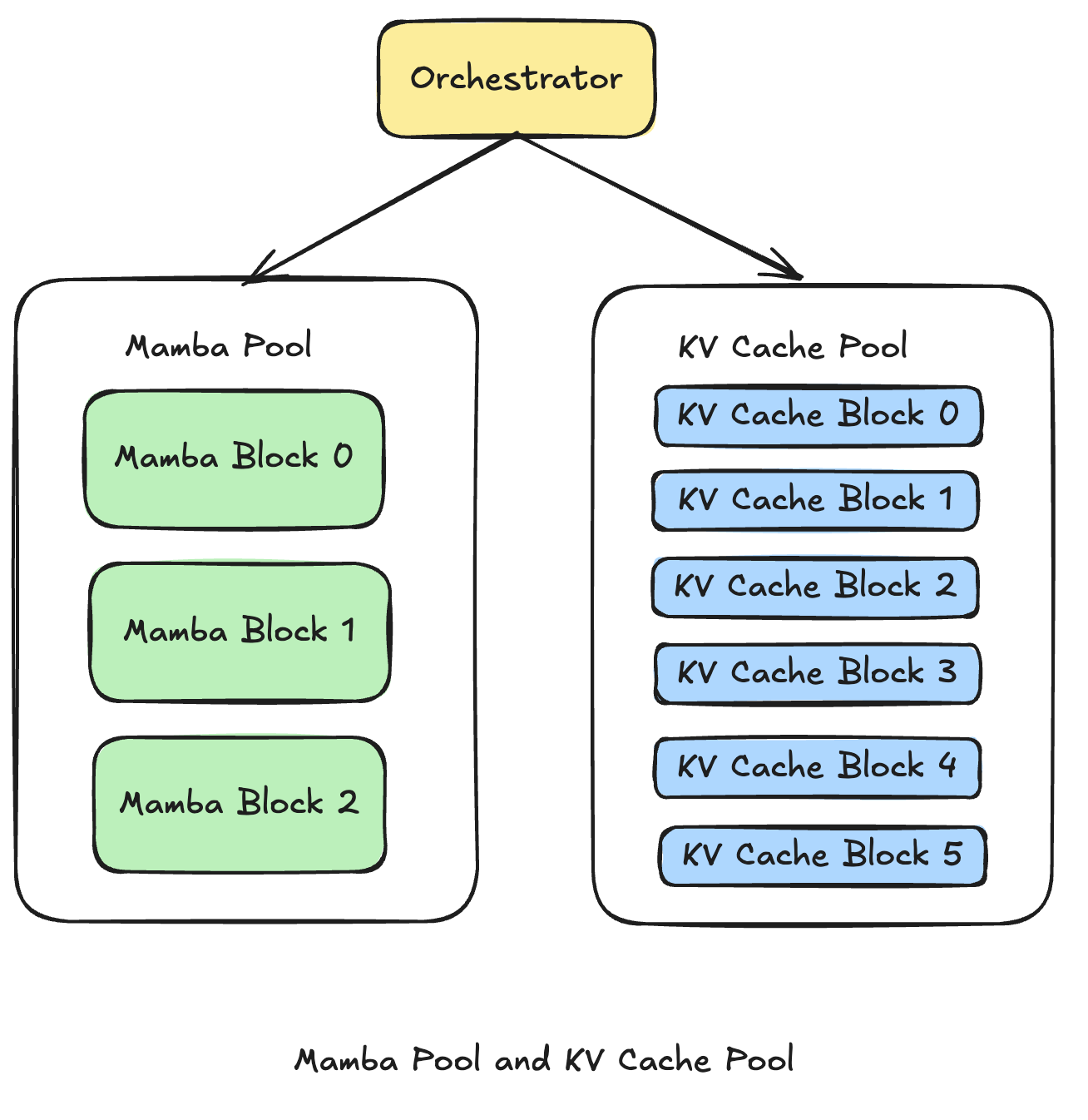
SGLang memory pool
Resource capacity
Another practical aspect is that Mamba pool is usually much more resource constrained than KV Cache pool. Recurrent states are much larger in size than the KV for a single token, which means Mamba pool have much fewer slots, faces more eviction pressure, and drives prefix reuse.
| Cache Pool | Slots | Total size |
|---|---|---|
| Mamba | 424 | 20.39 GB |
| KV | 740752 | 22.60 GB |
SGLang cache capacity breakdown (Qwen3.5-9B, 1xH100)
Cache Eviction Behavior
SGLang also treats KV cache and recurrent state very differently during eviction.
KV eviction
- Only applies to leaf nodes
- Removes both KV cache and recurrent state
- Deletes the node entirely
Mamba eviction
- Can target both leaf and internal nodes
- Removes only the recurrent state
- Leaves the internal node and its KV Cache intact
This creates tombstone nodes - internal nodes that still have KV cache, but no recurrent state.
Prefix Matching
For hybrid models, reuse requires:
- KV cache for all prefix tokens
- and a recurrent state that exactly matches the prefix
Reuse can only proceed up to the deepest node that still has a valid recurrent state. Even KV prefix may extend through tombstone nodes, reuse stops once you hit a tombstone node. Everything beyond that point has to be recomputed.
Integration Considerations
When we implement Marconi in SGLang (using Qwen/Qwen3.5-9B), a few practical considerations showed up.
First, tombstone nodes complicate the scoring logic.
Marconi’s FLOP-efficiency assumes parent nodes are valid. But in SGLang, that’s not always true due to tombstone nodes. The true recomputation distance may extend far beyond the immediate parent.
Second, FLOP estimation is model-specific.
Accurately computing FLOPs requires architecture-specific logic. In practice, hybrid models can vary significantly. Some use sequence modeling mechanisms like Mamba or Gated Delta Networks (GDN), while others use different feed-forward designs such as MoE. This makes it difficult to define a single, general-purpose FLOP estimate. As a result, the eviction policy becomes tightly coupled to model details and harder to maintain.
SegLen: A Simpler Heuristic
The core idea from Marconi is simple: states that represent longer prefixes tend to save more FLOPs per memory byte. So instead of computing FLOPS exactly, we looked for a simpler signal that captures the core idea.
We proposed a heuristic seglen that uses the replay distance to the nearest parent node that still has a valid recurrent state as a heuristic approximation to Marconi’s FLOPs-efficiency score.
Seglen naturally favors keeping entries that represent longer prefixes, which save more recomputation and is therefore more valuable to keep.
To make eviction decisions, seglen combines replay distance with recency — similar to Marconi, but without requiring model-specific FLOP estimation.
Here’s a simple example showing how different eviction policies behave:
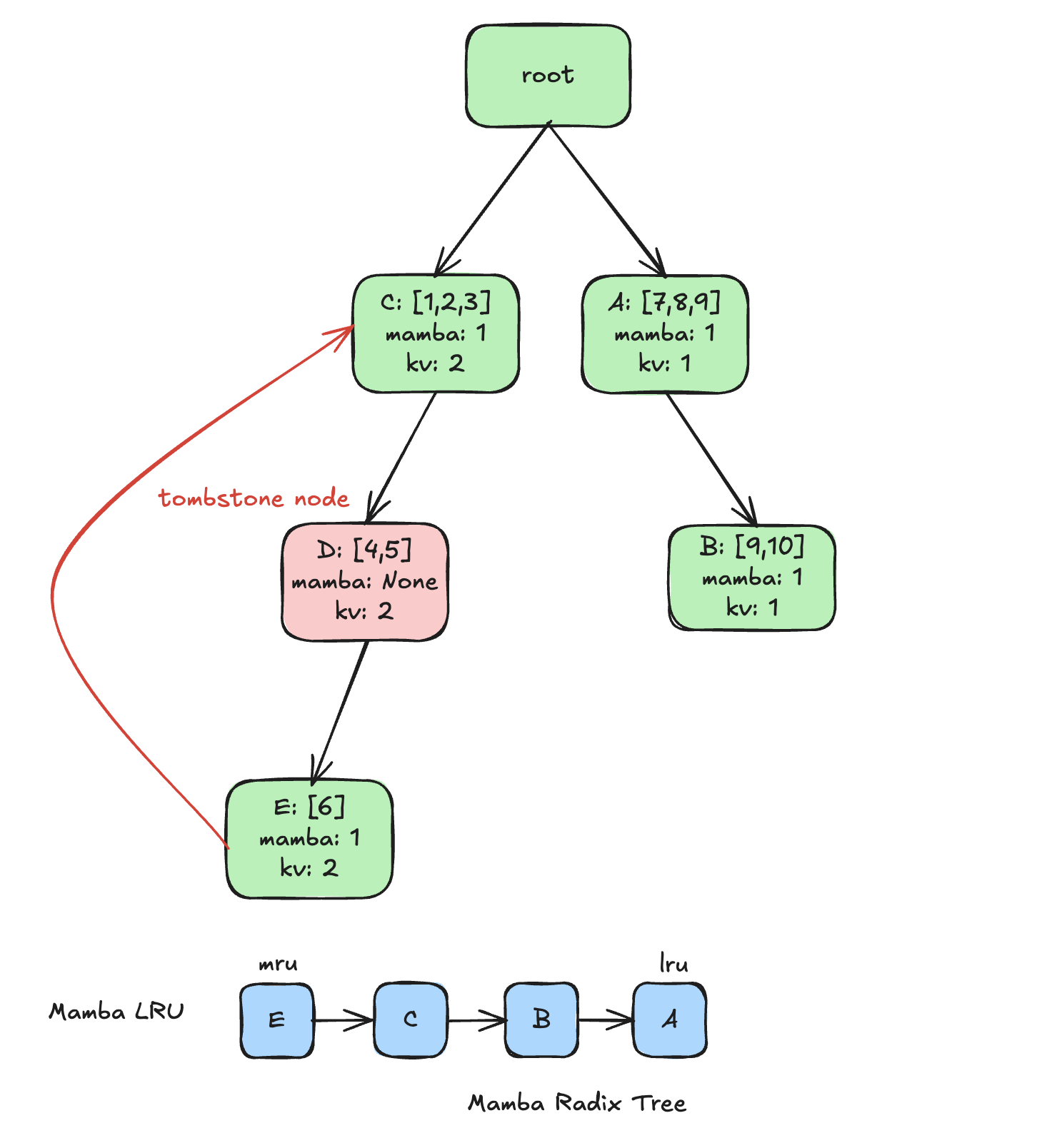
| Eviction policy | Ranking (best → worst to keep) | Eviction pick |
|---|---|---|
| LRU | E (mru) -> C -> B -> A (lru) | A |
| Marconi | C (efficiency=0.35) -> A (efficiency=0.32) -> B (efficiency=0.22) -> E (efficiency=0.15) | E |
| SegLen | E (seglen=3) -> C (seglen=3) -> A (seglen=3) -> B (seglen=2) | B |
When eviction is needed
- LRU picks A — the least recently used node
- Marconi picks E — its 1-token segment yields the lowest utility score
- SegLen picks B — its replay distance combined with recency is the smallest
The implementation of SegLen can be found here.
Experiments
Setup
We evaluate seglen against marconi and lru in SGLang using Qwen/Qwen3.5-9B model on a single H100 GPU.
Our goal is to understand how different cache policies behave under different workloads and memory constraints.
Across Workloads
We evaluate across two types of workloads:
- SWE-bench traces: realistic workloads with meaningful prefix reuse
- ShareGPT with low prefix reuse: a regression check in the low-reuse regime
Across these workloads, SegLen consistently reduces mean TTFT compared to LRU, achieving over 50% reduction on SWE-bench traces, while remaining competitive in low-reuse settings.
SWE-Bench
On swe-bench traces where each prefix is reused ~5 times on average, seglen reduced TTFT by 51.3% compared to lru, while also improving cache hit rate and reducing queue depth.
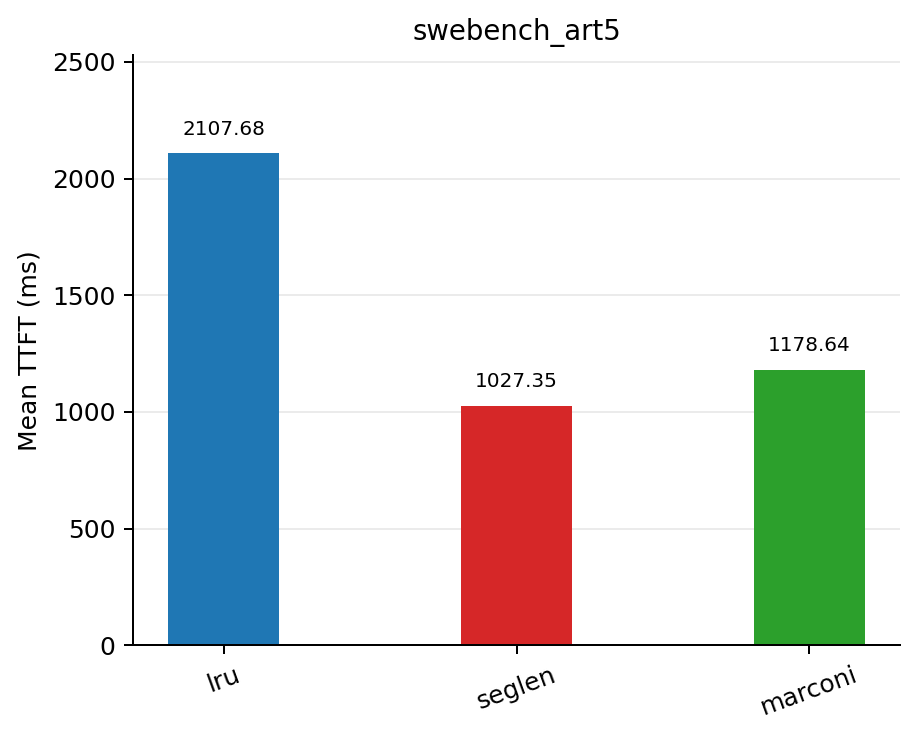
| Policy | Mean TTFT (ms) | Mean queue depth | Mean cache hit rate |
|---|---|---|---|
| lru | 2107.68 | 10.3686 | 0.3261 |
| seglen | 1027.35 | 4.8386 | 0.4179 |
| marconi | 1178.64 | 5.6679 | 0.4065 |
Results on swebench_sps=10_art=5_nums=100.jsonl dataset
On swe-bench trace where each prefix is reused ~10 times, seglen reduced TTFT by 51.5% compared to lru.
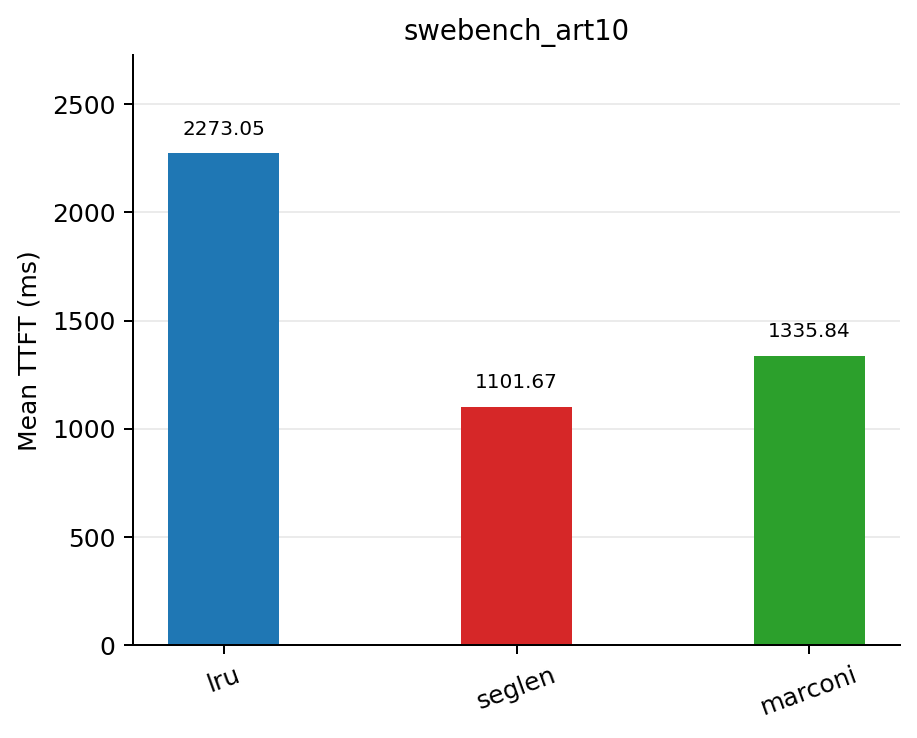
| Policy | Mean TTFT (ms) | Mean queue depth | Mean cache hit rate |
|---|---|---|---|
| lru | 2273.05 | 11.2514 | 0.2994 |
| seglen | 1101.67 | 5.9165 | 0.4353 |
| marconi | 1335.84 | 7.2620 | 0.4242 |
Results on swebench_sps=10_art=10_nums=100.jsonl dataset
ShareGPT
On ShareGPT dataset, where prefix reuse is minimal, SegLen remains competitive and achieves a 0.12% reduction in TTFT compared to lru.
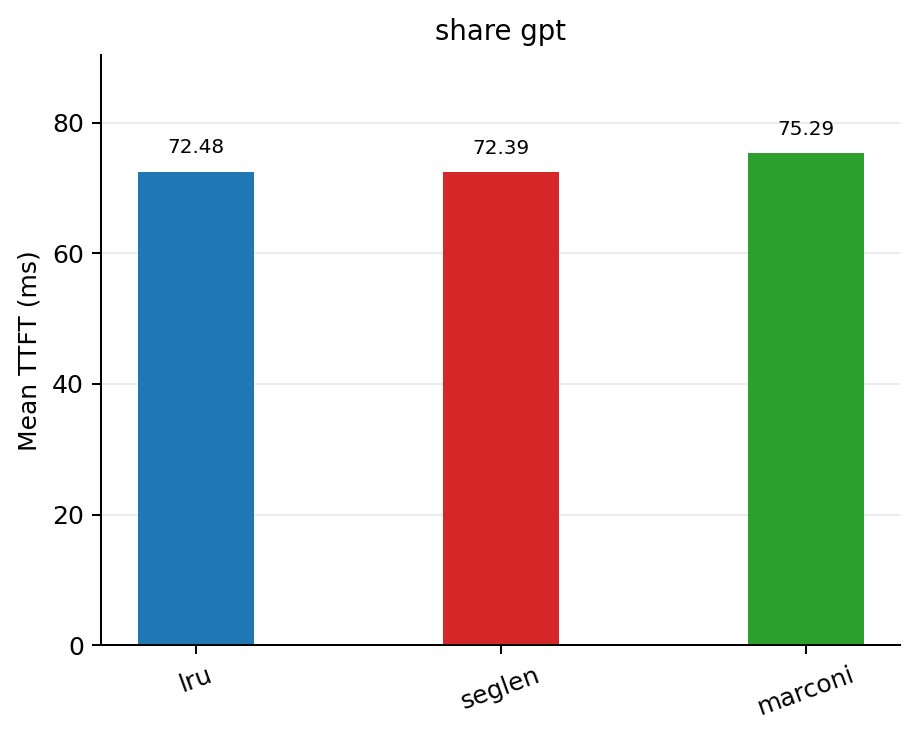
| Policy | Mean TTFT (ms) | Mean queue depth | Mean cache hit rate |
|---|---|---|---|
| lru | 72.48 | 0.0004 | 0.0022 |
| seglen | 72.39 | 0.0000 | 0.0049 |
| marconi | 75.29 | 0.0004 | 0.0049 |
Results on ShareGPT_V3_unfiltered_cleaned_split.json dataset
These results show that when prefix reuse is present, SegLen delivers significant performance gains. When reuse is low, it still remains competitive.
Across Memory Budgets
Next, we vary available cache memory to understand how policies behave under different levels of memory pressure.
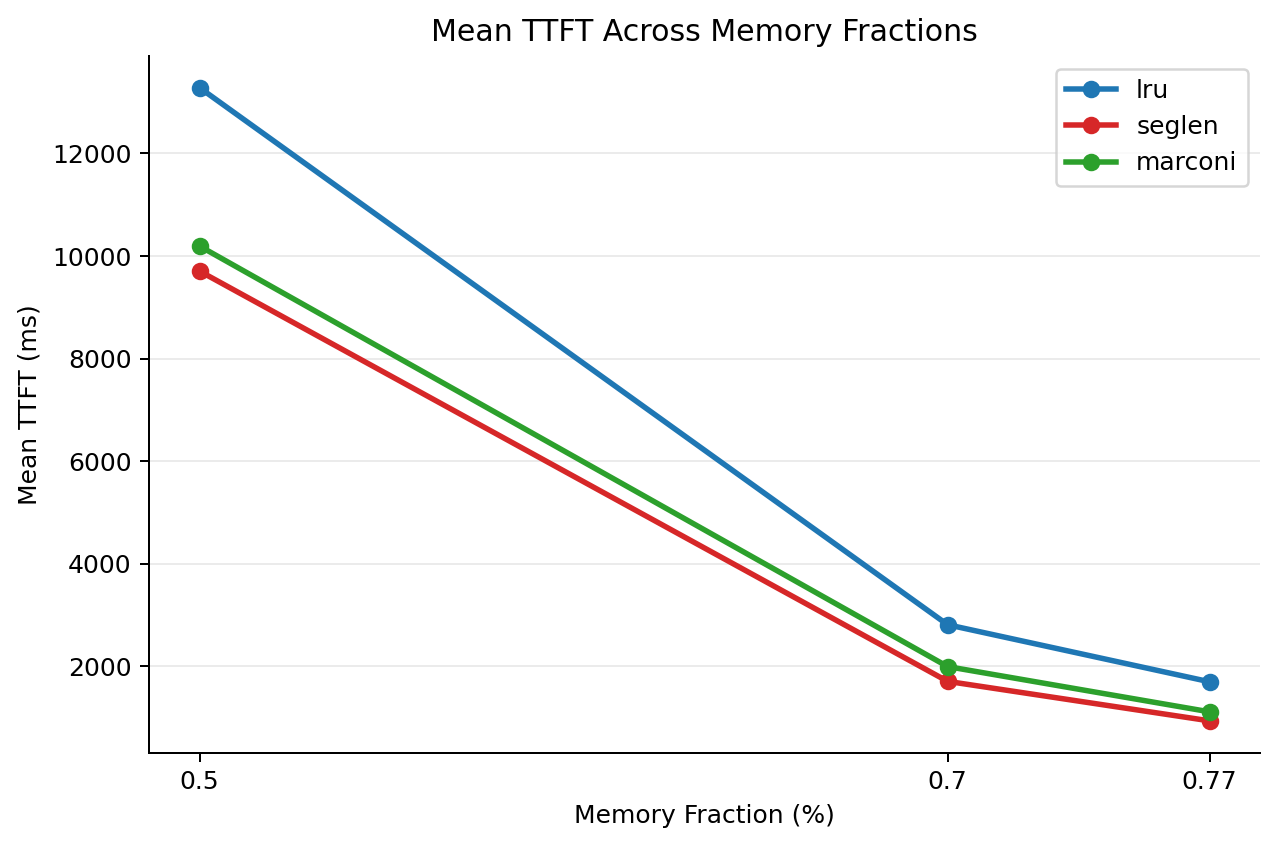
| Mem fraction static | Policy | Mean TTFT (ms) | Mean queue depth | Mean cache hit rate |
|---|---|---|---|---|
| 0.77 | lru | 1697.04 | 8.4729 | 0.3317 |
| 0.77 | seglen | 934.93 | 4.6355 | 0.4226 |
| 0.77 | marconi | 1110.74 | 5.4124 | 0.4088 |
| 0.7 | lru | 2809.16 | 14.3618 | 0.2912 |
| 0.7 | seglen | 1704.70 | 9.0218 | 0.3775 |
| 0.7 | marconi | 1992.97 | 10.1597 | 0.3835 |
| 0.5 | lru | 13283.69 | 58.0286 | 0.1290 |
| 0.5 | seglen | 9706.63 | 44.9238 | 0.2249 |
| 0.5 | marconi | 10194.86 | 46.8752 | 0.2238 |
Results on swebench_sps=10_art=5_nums=100.jsonl dataset
The trend is clear: as memory pressure increases, the advantage of seglen becomes more pronounced. This matches the intuition behind SegLen: when memory is tight, eviction decisions matter more, and better approximations of recomputation cost lead to larger gains.
Reproducibility
Driver scripts:
Bench-serving changes for swe-bench traces support:
Datasets
- https://huggingface.co/datasets/Isabella5/sglang-seglen-benchmark
Conclusion
Prefix caching works well for attention-only models, but hybrid architectures introduce a new challenge: recurrent states make reuse all-or-nothing, leading to large, sparsely utilized cache entries.
Marconi provides a key insight: cache eviction should be guided by recomputation cost, not just recency. Building on this idea, we propose SegLen, a simple heuristic that captures this core intuition while being much easier to integrate into a real serving system like SGLang.
Across our experiments, SegLen achieves over 50% reduction in TTFT on real workloads, remains competitive in low-reuse settings, and shows even larger gains under memory pressure.
In the end, SegLen shows that a simple heuristic is enough to capture the right signal and works well in a real serving system.
References
[1] Rui Pan, Zhuang Wang, Zhen Jia, Can Karakus, Luca Zancato, Tri Dao, Yida Wang, and Ravi Netravali. Marconi: Prefix Caching for the Era of Hybrid LLMs. 2024.
Citing
@misc{abdelfattah2026seglen,
title={Rethinking Prefix Caching for Hybrid LLMs},
author={Isabella Qiao and Crystal Zhou and Chi-Chih Chang and Mohamed Abdelfattah},
year={2026},
url={https://abdelfattah-lab.github.io/blog/seglen},
}